الذكاء الاصطناعي + الويب3: البرج والميدان
في الختام،
- مشاريع Web3 ذات مفهوم الذكاء الاصطناعي أصبحت أهداف استثمارية جذابة في الأسواق الأولية والثانوية.
- الفرص ل Web3 في صناعة الذكاء الاصطناعي تكمن في: استخدام الحوافز الموزعة لتنسيق العرض المحتمل في الذيل الطويل - عبر البيانات والتخزين والحسابات؛ في الوقت نفسه، إنشاء نموذج مفتوح المصدر وسوق متمركز لوكلاء الذكاء الاصطناعي.
- تلعب الذكاء الاصطناعي دوراً رئيسياً في صناعة الويب3، وذلك أساسا في مجال التمويل على السلسلة (المدفوعات بالعملات الرقمية، التداول، تحليل البيانات) ومساعدة التطوير.
- فائدة تقنية الذكاء الاصطناعي + الويب3 تكمن في التكامل بين الاثنين: من المتوقع أن يعمل الويب3 على مواجهة تمركز الذكاء الاصطناعي، ومن المتوقع أن يساعد الذكاء الاصطناعي الويب3 على التحرر من القيود.
مقدمة
في السنتين الماضيتين، تم تسريع تطوير الذكاء الاصطناعي، مثل تأثير الفراشة الذي بدأه Chatgpt، ليس فقط بفتح عالم جديد من الذكاء الاصطناعي التوليدي ولكن أيضًا بإثارة اتجاه في Web3 البعيد.
بفضل مفهوم الذكاء الاصطناعي، تم تعزيز تمويل سوق العملات المشفرة بشكل كبير مقارنة بالتباطؤ. وفقًا لإحصاءات الإعلام، في النصف الأول من عام 2024 وحده، أكمل مجموع 64 مشروعًا Web3+AI التمويل، وحققت نظام التشغيل Zyber365 القائم على الذكاء الاصطناعي أعلى مبلغ تمويل بقيمة 100 مليون دولار أمريكي في الجولة الأولى من التمويل السلسلي A.
السوق الثانوية أكثر ازدهارا ، وتظهر البيانات من موقع التجميع المشفر Coingecko أنه في ما يزيد قليلا عن عام ، وصلت القيمة السوقية الإجمالية لمسار الذكاء الاصطناعي إلى 485 مليار دولار ، بحجم تداول على مدار 24 ساعة يبلغ حوالي 86 مليار دولار. الفوائد الواضحة التي جلبها تقدم تكنولوجيا الذكاء الاصطناعي السائدة ، بعد إصدار نموذج تحويل النص إلى فيديو Sora من OpenAI ، ارتفع متوسط سعر قطاع الذكاء الاصطناعي بنسبة 151٪. انتشر تأثير الذكاء الاصطناعي أيضا إلى أحد قطاعات امتصاص الذهب للعملات المشفرة Meme: سرعان ما أصبح مفهوم وكيل الذكاء الاصطناعي MemeCoin - GOAT شائعا وحقق تقييما قدره 1.4 مليار دولار ، مما أدى بنجاح إلى جنون الذكاء الاصطناعي Meme.
البحث والمواضيع حول AI+Web3 ساخنة بالمثل. من AI+Depin إلى AI Memecoin وحتى AI Agent الحالي و AI DAO، فقد تخلفت عاطفة FOMO بالفعل وراء سرعة دورة السرد الجديدة.
AI+Web3، هذا التوازن بين المصطلحات المليء بالأموال الساخنة والاتجاهات والخيالات المستقبلية، يُنظر إليه بالضرورة كزواج ترتبه رأس المال. يبدو أنه من الصعب علينا التمييز بين ما إذا كانت هذه أرض العقاريين المختصين أم هي عشية الفجر تحت هذه الثوب الرائع.
للإجابة على هذا السؤال، يعد الاعتبار الرئيسي لكلا الطرفين هو ما إذا كان الآخر سيصبح أفضل؟ هل يمكن أن يستفيدوا من أنماط بعضهما البعض؟ في هذه المقالة، نحاول أيضًا فحص هذا الموقف من زاوية الوقوف على كتفي السلف: كيف يمكن لـ Web3 أن تلعب دورًا في مختلف جوانب تراكم التقنية الذكية، وما هي الحيوية الجديدة التي يمكن للذكاء الاصطناعي أن يجلبها إلى Web3؟
ما هي الفرص التي يحظى بها Web3 تحت مجموعة AI؟
قبل أن نغوص في هذا الموضوع، نحتاج إلى فهم الكومة الفنية لنماذج الذكاء الاصطناعي الكبيرة:
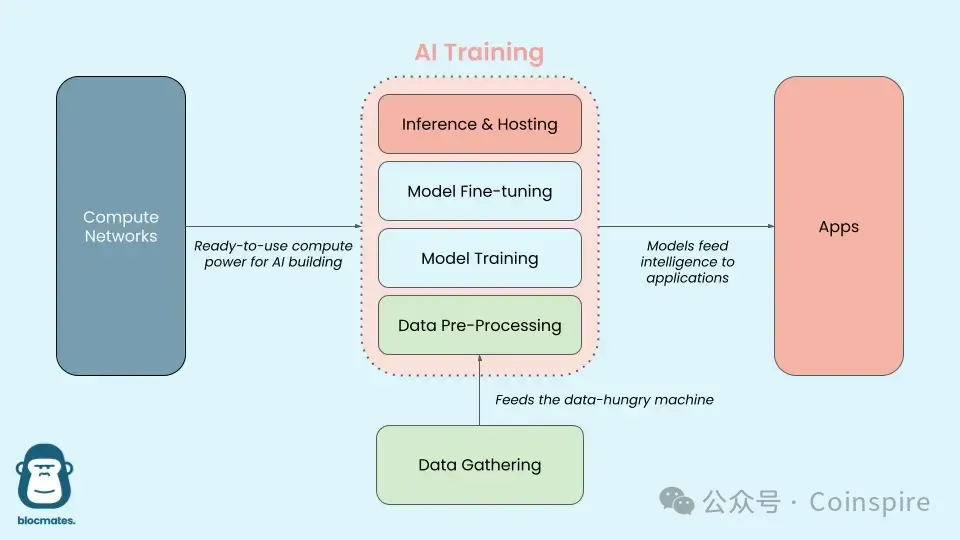
مصدر الصورة: Delphi Digital
ببساطة، يشبه "النموذج الكبير" الدماغ البشري. في المراحل الأولى، يشبه هذا الدماغ طفلاً رضيعًا للتو قد جاء إلى العالم، حيث يحتاج إلى ملاحظة واستيعاب كميات هائلة من المعلومات الخارجية لفهم العالم. هذه هي مرحلة "الجمع" للبيانات؛ حيث أن الحواسيب لا تمتلك حواس متعددة مثل البشر، فقبل التدريب، يحتاج إلى "معالجة مسبقة" للمعلومات الخارجية غير المحددة على نطاق واسع لتحويلها إلى شكل يمكن للحواسيب فهمه واستخدامه.
بعد إدخال البيانات، يقوم الذكاء الاصطناعي ببناء نموذج يتمتع بالقدرة على فهم والتنبؤ من خلال 'التدريب'، والذي يمكن اعتباره عملية يفهم فيها الطفل تدريجياً ويتعلم عن العالم الخارجي. معلمات النموذج تشبه قدرة اللغة التي يعدلها الطفل باستمرار خلال عملية التعلم. عندما يبدأ محتوى التعلم في التخصص، أو عندما يتلقى ردود فعل من التفاعل مع الناس ويقوم بإجراء تصحيحات، يدخل مرحلة 'ضبط الدقة' للنماذج الكبيرة.
بينما ينمو الأطفال ويتعلمون الكلام، يمكنهم فهم المعاني والتعبير عن مشاعرهم وأفكارهم في محادثات جديدة، وهذا يشبه 'استنتاج' النماذج الذكاء الاصطناعي الكبيرة. يمكن للنموذج التنبؤ وتحليل المدخلات اللغوية والنصية الجديدة. يعبر الأطفال الرضع عن مشاعرهم، ويصفون الأشياء، ويحلون مشاكل مختلفة من خلال قدرات اللغة، وهذا يشبه أيضًا تطبيق النماذج الذكاء الاصطناعي الكبيرة في مهام محددة مختلفة خلال مرحلة الاستنتاج بعد الانتهاء من التدريب، مثل تصنيف الصور، والتعرف على الكلام، وما إلى ذلك.
بينما يقترب وكيل الذكاء الاصطناعي من الشكل القادم للنماذج الكبيرة - القدرة على تنفيذ المهام بشكل مستقل ومتابعة الأهداف المعقدة، ليس فقط امتلاك القدرة على التفكير، ولكن أيضًا القدرة على تذكر والتخطيط، والتفاعل مع العالم باستخدام الأدوات.
حالياً، ومعالجة نقاط الألم في الذكاء الاصطناعي في مختلف الأنظمة، شكلت Web3 بشكل أولي نظام بيئي متعدد الطبقات ومترابط، يغطي مراحل مختلفة من عمليات نموذج الذكاء الاصطناعي.
الطبقة الأولى: Airbnb لقوة الحوسبة والبيانات
قوة الحوسبة
حاليًا، أحد أعلى تكاليف الذكاء الاصطناعي هو القوة الحاسوبية والطاقة اللازمة لتدريب النماذج ونماذج الاستنتاج.
مثال واحد هو أن LLAMA3 من Meta يتطلب 16,000 H100GPUs التي أنتجتها NVIDIA (وحدة معالجة رسومات رائدة مصممة خصيصًا لأنظمة الذكاء الاصطناعي وأعباء الحوسبة عالية الأداء) لإكمال التدريب في 30 يومًا. إصدار 80 جيجابايت من الإصدار السابق يتراوح سعره بين 30,000 و 40,000 دولار ، مما يتطلب استثمارًا في الأجهزة بقيمة 4-7 مليارات دولار (GPU + رقائق الشبكة). بالإضافة إلى ذلك ، يتطلب التدريب الشهري استهلاكًا يصل إلى 16 مليار كيلووات-ساعة ، مع نفقات طاقة تبلغ ما يقرب من 20 مليون دولار شهريًا.
لفك ضغط قوة الحوسبة الذكية الاصطناعية، فإنه أيضًا أقدم مجال حيث يتقاطع Web3 مع الذكاء الاصطناعي - DePin (شبكة البنية التحتية اللامركزية). حاليًا، عرض موقع DePin Ninja للبيانات أكثر من 1400 مشروع، بما في ذلك مشاريع ممثلة لمشاركة قوة الحوسبة GPU مثل io.net، Aethir، Akash، Render Network، وما إلى ذلك.
المنطق الرئيسي هو: تتيح المنصة للأفراد أو الكيانات الذين يمتلكون موارد GPU الخاملة إسهام قوتهم الحاسوبية بطريقة لامركزية بدون إذن، مما يزيد من استخدام موارد GPU الغير مستخدمة بشكل كامل من خلال سوق عبر الإنترنت مشابه لـ Uber أو Airbnb للمشترين والبائعين، مما يتيح للمستخدمين النهائيين الحصول على موارد حوسبة أكثر كفاءة وكلفة فعالة؛ في الوقت نفسه، يضمن آلية الرهان أيضًا أنه في حالة وجود انتهاكات لآليات مراقبة الجودة أو انقطاعات الشبكة، سيواجه مقدمو الموارد عقوبات مقابلة.
ميزاتها هي:
- تجميع موارد وحدة المعالجة الرسومية الخاملة: يتمثل الموردون في المركز البيانات الصغيرة والمتوسطة المستقلة من جهات خارجية بشكل رئيسي، وفائض موارد الطاقة الحسابية من المشغلين مثل المناجم المشفرة، وأجهزة التعدين ذات آليات توافق PoS، مثل FileCoin ومنقبي ETH. حاليًا، هناك أيضًا مشاريع مخصصة لإطلاق أجهزة بحدود دخول أقل، مثل exolab الذي يستخدم الأجهزة المحلية مثل MacBook و iPhone و iPad لإنشاء شبكة طاقة حوسبة لتشغيل استنتاجات نموذج كبيرة الحجم.
- Enfrentando el mercado de cola larga del poder de cálculo de la IA: a. "En términos de tecnología", el mercado de poder de cálculo descentralizado es más adecuado para pasos de razonamiento. El entrenamiento depende más de la capacidad de procesamiento de datos aportada por el super gran clúster de GPU a escala, mientras que el razonamiento es relativamente bajo en rendimiento de cálculo de GPU, como Aethir que se centra en trabajos de renderizado de baja latencia y aplicaciones de inferencia de IA. b. "En términos de demanda", los demandantes de poder de cálculo pequeños y medianos no entrenarán individualmente sus propios modelos grandes, sino que solo elegirán optimizar y ajustar alrededor de unos pocos modelos principales, y estos escenarios son naturalmente adecuados para los recursos distribuidos de poder de cálculo inactivo.
- الملكية اللامركزية: الأهمية التكنولوجية للبلوكشين هي أن أصحاب الموارد يحتفظون دائمًا بالسيطرة على مواردهم، ويعدلون بمرونة وفقًا للطلب، ويحققون ربحًا في الوقت نفسه.
البيانات
البيانات هي أساس الذكاء الاصطناعي. بدون بيانات، التحسيب لا جدوى منه، والعلاقة بين البيانات والنماذج تشبه المثل 'الزبالة داخل، الزبالة خارج'. كمية وجودة البيانات تحدد جودة الناتج للنموذج النهائي. بالنسبة لتدريب النماذج الحالية للذكاء الاصطناعي، تحدد البيانات القدرة على اللغة، القدرة على الفهم، وحتى القيم والأداء المؤهل للإنسان الخاص بالنموذج. في الوقت الحالي، يركز معضل الطلب على البيانات في الذكاء الاصطناعي بشكل أساسي على الجوانب الأربعة التالية:
- جوع البيانات: تعتمد تدريب نموذج الذكاء الاصطناعي بشكل كبير على كميات كبيرة من البيانات المدخلة. تشير المعلومات العامة إلى أن عدد المعلمات الخاصة بتدريب GPT-4 من OpenAI قد وصل إلى مستوى التريليون.
- جودة البيانات: مع توافق الذكاء الاصطناعي ومختلف الصناعات، تم طرح متطلبات جديدة لقابلية الوقت، التنوع، الاحترافية للبيانات الخاصة بالصناعة، واستيعاب مصادر البيانات الناشئة مثل مشاعر وسائل التواصل الاجتماعي.
- قضايا الخصوصية والامتثال: حاليًا، تدرك مختلف الدول والشركات تدريجيًا أهمية مجموعات البيانات عالية الجودة وتفرض قيودًا على جمع البيانات.
- تكاليف معالجة البيانات العالية: كميات كبيرة من البيانات، معالجة معقدة. تشير المعلومات العامة إلى أن أكثر من 30% من تكاليف البحث والتطوير لشركات الذكاء الاصطناعي تُستخدم لجمع البيانات الأساسية ومعالجتها.
حالياً، تتمثل حلاً لـ web3 في الجوانب الأربعة التالية:
1. جمع البيانات: البيانات الحقيقية المتاحة بشكل حر للحصول عليها بسرعة تنفد، وتزداد نفقات شركات الذكاء الاصطناعي للبيانات من عام إلى آخر. ومع ذلك، في الوقت نفسه، لم يتم تحويل هذه النفقات إلى مساهمي البيانات الحقيقيين؛ حيث استمتعت المنصات بالقيمة التي جلبتها البيانات، مثل Reddit الذي حقق إجمالي 203 مليون دولار من إيرادات التراخيص للبيانات مع شركات الذكاء الاصطناعي.
رؤية ويب 3 هي السماح للمستخدمين الذين يساهمون حقًا أيضًا في المشاركة في إنشاء القيمة التي يجلبها البيانات، والحصول على بيانات المستخدمين الشخصية والقيمة بشكل أكثر كفاءة من خلال الشبكات الموزعة وآليات الحوافز.
- كون العشب طبقة بيانات لامركزية وشبكة، يمكن للمستخدمين التقاط البيانات في الوقت الحقيقي من الإنترنت بأكمله عن طريق تشغيل عقد العشب، والمساهمة في عرض النطاق الترددي الخامل وإعادة توجيه حركة المرور، واستلام مكافآت الرموز؛
- فانا تقدم مفهوم فريد لبركة سيولة البيانات (DLP)، حيث يمكن للمستخدمين رفع بياناتهم الخاصة (مثل سجلات التسوق، عادات التصفح، أنشطة وسائل التواصل الاجتماعي، إلخ) إلى DLP محددة واختيارياً اختيار ما إذا كانوا يأذنون باستخدام هذه البيانات لجهة خارجية محددة؛
- في PublicAI، يمكن للمستخدمين استخدام #AI أو #Web3 كعلامات تصنيف على X@PublicAIيمكن تحقيق جمع البيانات.
2. المعالجة المسبقة للبيانات: في معالجة بيانات الذكاء الاصطناعي ، نظرا لأن البيانات التي تم جمعها عادة ما تكون صاخبة وتحتوي على أخطاء ، يجب تنظيفها وتحويلها إلى تنسيق قابل للاستخدام قبل تدريب النموذج ، بما في ذلك المهام المتكررة المتمثلة في التوحيد القياسي والتصفية والتعامل مع القيم المفقودة. هذه المرحلة هي واحدة من العمليات اليدوية القليلة في صناعة الذكاء الاصطناعي ، والتي أنتجت صناعة معلقي البيانات. مع زيادة متطلبات النموذج لجودة البيانات ، ترتفع أيضا عتبة معلقي البيانات. هذه المهمة تفسح المجال بشكل طبيعي لآلية الحوافز اللامركزية ل Web3.
- حالياً، Grass و OpenLayer يفكران في إضافة تعليقات البيانات كخطوة رئيسية.
- اقترحت Synesis مفهوم 'Train2earn'، مشددة على جودة البيانات، حيث يمكن للمستخدمين الحصول على مكافأة عن طريق تقديم بيانات محددة، تعليقات، أو أشكال أخرى من المدخلات.
- يقوم مشروع تسمية البيانات Sapien بتحويل مهام التسمية إلى لعبة ويسمح للمستخدمين برهان النقاط لكسب المزيد من النقاط.
3. الخصوصية والأمان في البيانات: يجب توضيح أن الخصوصية والأمان في البيانات هما مفهومان مختلفان. تنطوي الخصوصية في البيانات على التعامل مع البيانات الحساسة، بينما يحمي الأمان في البيانات معلومات البيانات من الوصول غير المصرح به، والتدمير، والسرقة. ونتيجة لذلك، تنعكس مزايا وسيناريوهات التطبيق المحتملة لتقنيات خصوصية Web3 في جانبين: (1) تدريب البيانات الحساسة؛ (2) تعاون البيانات: يمكن لمالكي البيانات المتعددين المشاركة في تدريب الذكاء الاصطناعي معًا دون مشاركة بياناتهم الأصلية.
تشمل التقنيات الشائعة للخصوصية في Web3 حاليًا:
- بيئة التنفيذ الموثوقة (TEE)، مثل بروتوكول سوبر؛
- التشفير الكامل للتشويش (FHE)، مثل BasedAI، Fhenix.io، أو Inco Network؛
- تقنية العلم الصفري (zk)، مثل بروتوكول Reclaim الذي يستخدم تقنية zkTLS، تولد دلائل العلم الصفري لحركة HTTPS، مما يسمح للمستخدمين باستيراد النشاط والسمعة وبيانات الهوية بشكل آمن من مواقع الويب الخارجية دون تعريض المعلومات الحساسة.
مع ذلك، لا يزال المجال في مراحله الأولى، مع معظم المشاريع لا تزال في مرحلة الاستكشاف. حاليًا، أحد الألغاز هو أن تكاليف الحوسبة مرتفعة للغاية، مع بعض الأمثلة على ذلك:
- الإطار zkML EZKL يستغرق حوالي 80 دقيقة لإنشاء دليل لنموذج 1M-nanoGPT.
- وفقًا لبيانات Modulus Labs ، يبلغ الزائد الزائد على zkML أكثر من 1000 مرة من الحساب النقي.
4. تخزين البيانات: بعد الحصول على البيانات، من الضروري أن يكون هناك مكان لتخزين البيانات على السلسلة واستخدام الLLM الذي تم إنشاؤه بواسطة البيانات. مع توافر البيانات (DA) كمسألة أساسية، قبل ترقية Ethereum Danksharding، كانت سرعة النقل الخاصة به 0.08 ميغابايت. في الوقت نفسه، فإن تدريب والاستدلال الزمني الفوري لنماذج الذكاء الاصطناعي عادةً ما يتطلب سرعة نقل بيانات تتراوح بين 50 و100 جيجابايت في الثانية. هذا الفرق في مقدار الطلب يجعل الحلول الحالية على السلسلة غير كافية عند مواجهة 'تطبيقات الذكاء الاصطناعي المستنفذة للموارد'.
- 0g.AI هو مشروع ممثل في هذه الفئة. إنه حلاً للتخزين المركزي مصمم لمتطلبات الذكاء الاصطناعي عالي الأداء، مع ميزات رئيسية تشمل الأداء العالي والتوسعة، ودعم رفع وتنزيل سريع لمجموعات بيانات كبيرة من خلال تقنيات التجزئة المتقدمة وتشفير المحو، مع سرعات نقل البيانات تصل إلى 5 غيغابايت في الثانية تقريبًا.
اثنان، وسيط البرمجيات: تدريب واستنتاج النموذج
نموذج مفتوح المصدر للسوق اللامركزية
لم يتوقف الجدل حول ما إذا كان يجب أن تكون نماذج الذكاء الاصطناعي مفتوحة المصدر أو مغلقة المصدر. يعد الابتكار الجماعي الذي يجلبه المصدر المفتوح ميزة لا يمكن لنماذج المصادر المغلقة مطابقتها. ومع ذلك ، في ظل فرضية نموذج عدم الربح ، كيف يمكن للنماذج مفتوحة المصدر أن تعزز تحفيز المطور؟ هذا اتجاه يستحق التفكير. أكد مؤسس بايدو ، روبن لي ، في أبريل من هذا العام ، أن "نماذج المصادر المفتوحة ستتخلف عن الركب أكثر فأكثر".
في هذا الصدد، تقترح Web3 إمكانية سوق نموذج مفتوح المصدر لامركزي، وهي عملة رقمية للنموذج نفسه، محجوزة نسبة معينة من الرموز للفريق، وتوجيه جزء من دخل المستقبل لحاملي الرموز.
- ينشئ بروتوكول Bittensor نموذجًا مفتوح المصدر لسوق P2P، يتألف من عشرات من 'الشبكات الفرعية'، حيث يتنافس موفرو الموارد (الحوسبة، وجمع / تخزين البيانات، ومواهب التعلم الآلي) مع بعضهم البعض لتحقيق أهداف أصحاب الشبكة الفرعية المحددة. يمكن للشبكات الفرعية التفاعل والتعلم من بعضها البعض، وبالتالي تحقيق ذكاء أكبر. يتم توزيع المكافآت عن طريق التصويت المجتمعي وتوزيعها بشكل أكبر بين الشبكات الفرعية بناءً على الأداء التنافسي.
- تقدم ORA مفهوم عرض النموذج الأولي (IMO) ، وترميز نماذج الذكاء الاصطناعي للشراء والبيع والتطوير على الشبكات اللامركزية.
- Sentient، منصة AGI لامركزية، تحفز الناس على التعاون والبناء والتكرار وتوسيع نماذج الذكاء الاصطناعي، مكافأة المساهمين.
- تركز سبيكترال نوفا على إنشاء وتطبيق نماذج الذكاء الاصطناعي وتعلم الآلة.
استنتاج قابل للتحقق
بالنسبة لمعضلة 'صندوق الأسود' في عملية التفكير الذكي، الحل القياسي في Web3 هو أن يكون هناك عدة محققين يكررون نفس العملية ويقارنون النتائج. ومع ذلك، نظرًا لنقص الحالي في 'شرائح نفيديا' عالية الجودة، التحدي الواضح الذي تواجهه هذه الطريقة هو التكلفة العالية لعملية التفكير الذكية.
حلاً أكثر وعدًا هو أداء دلائل ZK لحسابات استنتاج الذكاء الاصطناعي خارج السلسلة، حيث يمكن لمثبت واحد أن يثبت لآخر محقق أن البيان المعطى صحيح دون الكشف عن أي معلومات إضافية سوى صحة البيان، مما يمكن من التحقق بدون إذن من حسابات نموذج الذكاء الاصطناعي على السلسلة. يتطلب ذلك إثباتًا في السلسلة بطريقة مشفرة أن الحسابات خارج السلسلة قد أكملت بشكل صحيح (على سبيل المثال، لم يتم تلاعب في مجموع البيانات)، مع ضمان سرية جميع البيانات.
المزايا الرئيسية تشمل:
- التوسع: يمكن للأدلة بدون معرفة تأكيد بسرعة عدد كبير من العمليات خارج السلسلة. حتى مع زيادة عدد المعاملات، يمكن لأدلة بدون معرفة واحدة التحقق من جميع المعاملات.
- حماية الخصوصية: يتم الاحتفاظ بمعلومات مفصلة حول البيانات ونماذج الذكاء الاصطناعي سرًا، بينما يمكن لجميع الأطراف التحقق من أن البيانات والنماذج لم يتم التلاعب بها.
- لا حاجة للثقة: يمكنك تأكيد الحساب دون الاعتماد على الأطراف المركزية.
- التكامل مع Web2: بموجب التعريف، يتم تكامل Web2 خارج السلسلة، مما يعني أن التفسير القابل للتحقق يمكن أن يساعد في جلب مجموعات بياناته وحسابات الذكاء الاصطناعي إلى السلسلة. يساعد هذا في تحسين اعتماد Web3.
حاليًا، تقنية Web3 للتحقق من الأمان للتفكير المحقق كالتالي:
- ZKML: دمج دليل الصفر المعرفي مع تعلم الآلة لضمان خصوصية وسرية البيانات والنماذج، مما يسمح بالحساب القابل للتحقق دون الكشف عن خصائص معينة تحتها. قد أطلقت Modulus Labs جهاز إثبات ZK مستندًا إلى ZKML لبناء الذكاء الاصطناعي، للتحقق بشكل فعال مما إذا كان مزودو الذكاء الاصطناعي على السلسلة يتلاعبون بالخوارزميات تم تنفيذها بشكل صحيح، ولكن حاليًا العملاء يكونون أساسًا على تطبيقات الذكاء الاصطناعي على السلسلة.
- opML: باستخدام مبدأ التجميع المتفائل، من خلال التحقق من وقت حدوث النزاع، وتحسين قابلية التوسع وكفاءة حسابات ML، في هذا النموذج، يجب التحقق فقط من جزء صغير من النتائج التي تم إنشاؤها بواسطة 'المحقق'، ولكن تم تعيين تخفيض التكلفة الاقتصادية بما يكفي لزيادة تكلفة الغش من قبل المحققين وتوفير الحسابات الزائدة.
- TeeML: استخدم بيئة التنفيذ الموثوقة لتنفيذ حسابات التعلم الآلي بأمان، مما يحمي البيانات والنماذج من التلاعب والوصول غير المصرح به.
ثلاثة، طبقة التطبيق: وكيل الذكاء الاصطناعي
أظهر تطور الذكاء الاصطناعي الحالي بالفعل تحولًا في التركيز من قدرات النموذج إلى مشهد وكلاء الذكاء الاصطناعي. تقوم شركات التكنولوجيا مثل OpenAI، وشركة الذكاء الاصطناعي Anthropic، وMicrosoft، وغيرها، بالانتقال إلى تطوير وكلاء الذكاء الاصطناعي، محاولةً اختراق هضبة التقنية الحالية لـ LLM.
تعرف OpenAI وكيل AI بأنه نظام يديره LLM كدماغ له، ولديه القدرة على فهم الإدراك بشكل مستقل، والتخطيط، والتذكر، واستخدام الأدوات، ويمكنه إكمال المهام المعقدة تلقائيًا. عندما ينتقل الذكاء الاصطناعي من كونه أداة مستخدمة إلى موضوع يمكنه استخدام الأدوات، يصبح وكيلاً للذكاء الاصطناعي. وهذا هو أيضًا السبب في أن وكلاء AI يمكن أن يصبحوا أفضل مساعدين ذكاء مثاليين للبشر.
ما الذي يمكن أن يجلبه Web3 إلى Agent؟
1. اللامركزية
يمكن أن يجعل تمزيق نظام الوكالة أكثر اتساقًا وتلقائية. يمكن أن آليات الحوافز والعقوبات للمراهنين والمندوبين تعزز ديمقراطية نظام الوكالة، مع GaiaNet، Theoriq، و HajimeAI جميعها تحاول القيام بذلك.
2، بدء بارد
تطوير وتكرار وكيل الذكاء الاصطناعي يتطلب في كثير من الأحيان كمية كبيرة من الدعم المالي، ويمكن لـ Web3 مساعدة مشاريع وكلاء الذكاء الاصطناعي الواعدة في الحصول على تمويل في مرحلة مبكرة وبدء بارد.
- تطلق Virtual Protocol منصة إنشاء وإصدار رمزية AI Agent fun.virtuals، حيث يمكن لأي مستخدم نشر AI Agents بنقرة واحدة وتحقيق توزيع عادل بنسبة 100% لرموز AI Agent.
- اقترحت سبيكترال مفهوم منتج يدعم إصدار أصول وكلاء الذكاء الاصطناعي على السلسلة: إصدار الرموز من خلال IAO (العرض الأولي للوكيل)، يمكن لوكلاء الذكاء الاصطناعي الحصول على الأموال مباشرة من المستثمرين، بينما يصبحون أعضاء في حوكمة DAO، وتوفير فرصة للمستثمرين للمشاركة في تطوير المشروع ومشاركة الأرباح المستقبلية.
كيف يمكن للذكاء الاصطناعي تمكين Web3؟
تأثير الذكاء الاصطناعي على مشاريع الويب3 واضح، حيث يعود بالفائدة على تكنولوجيا البلوكشين من خلال تحسين العمليات على السلسلة (مثل تنفيذ العقود الذكية، وتحسين السيولة، واتخاذ قرارات الحكم بدفعة من الذكاء الاصطناعي). في الوقت نفسه، يمكن أيضا أن يوفر رؤى أفضل قائمة على البيانات، وتعزيز الأمان على السلسلة، ووضع الأسس لتطبيقات جديدة معتمدة على الويب3.
واحد، الذكاء الاصطناعي والتمويل على السلسلة
الذكاء الاصطناعي والاقتصاد الرقمي
في 31 أغسطس، أعلن الرئيس التنفيذي لـ كوينبيس، برايان أرمسترونغ، عن أول عملية تشفير AI-to-AI على شبكة Base، مشيرًا إلى أن وكلاء الذكاء الاصطناعي الآن يمكنهم التعامل مع البشر أو التجار أو غيرهم من الذكاءات الاصطناعية على Base باستخدام الدولار الأمريكي، مع الصفقات تكون فورية وعالمية ومجانية.
بالإضافة إلى المدفوعات، أظهرت لونا من بشكل أولي كيفية تنفيذ وكلاء الذكاء الاصطناعي المعاملات على السلسلة الكتلية بشكل مستقل، مما جذب الانتباه ووضع وكلاء الذكاء الاصطناعي ككيانات ذكية قادرة على استيعاب البيئة، اتخاذ القرارات، واتخاذ الإجراءات، وبالتالي يُنظر إليها على أنها مستقبل التمويل على السلسلة الكتلية. حاليًا، السيناريوهات المحتملة لوكلاء الذكاء الاصطناعي هي كما يلي:
1. جمع المعلومات والتنبؤ: مساعدة المستثمرين في جمع الإعلانات التبادلية، والمعلومات العامة حول المشروعات، والعواطف الهلع، ومخاطر الرأي العام، وما إلى ذلك، وتحليل وتقييم أساسيات الأصول، وظروف السوق في الوقت الحقيقي، والتنبؤ بالاتجاهات والمخاطر.
2. إدارة الأصول: توفير أهداف استثمار مناسبة للمستخدمين، وتحسين توزيع الأصول، وتنفيذ الصفقات تلقائيًا.
3. الخبرة المالية: مساعدة المستثمرين في اختيار أسرع طريقة للتداول على السلسلة، وتوطين العمليات اليدوية مثل المعاملات عبر السلاسل وضبط رسوم الغاز تلقائيًا، وتقليل عتبة وتكلفة الأنشطة المالية على السلسلة.
تخيل هذا السيناريو: توجه العميل الذكاء الصناعي كما يلي، 'لدي 1000USDT، يرجى مساعدتي في العثور على التركيبة الأعلى عائدًا مع فترة قفل لا تزيد عن أسبوع واحد.' سيقدم العميل الذكاء الصناعي النصيحة التالية: 'أقترح تخصيصًا أوليًا بنسبة 50٪ في A، 20٪ في B، 20٪ في X، و 10٪ في Y. سأراقب معدلات الفائدة وألاحظ التغيرات في مستويات المخاطر الخاصة بها، وأعادل التوازن عند الضرورة.' بالإضافة إلى ذلك، البحث عن مشاريع الهبوط الجوي المحتملة وعلامات المجتمع الشعبية لمشاريع Memecoin كلها إجراءات مستقبلية ممكنة للعميل الذكاء الصناعي.

مصدر الصورة: Biconomy
حاليًا، تقوم محافظ AI Agent Bitte وبروتوكول التفاعل AI Wayfinder بمثل هذه المحاولات. جميعها تحاول الوصول إلى واجهة برمجة تطبيقات نموذج OpenAI، مما يتيح للمستخدمين أن يأمروا الوكلاء بإكمال مختلف العمليات على السلسلة الرئيسية في واجهة نافذة دردشة مشابهة لـ ChatGPT. على سبيل المثال، أظهرت النموذج الأولي الذي أطلقته WayFinder في أبريل هذا العام أربع عمليات أساسية: تبديل، إرسال، جسر، ورهن على شبكات Base وPolygon وEthereum.
حاليًا، تدعم منصة الوكيل اللامركزية Morpheus أيضًا تطوير مثل هذه الوكلاء، كما يظهر ذلك من خلال Biconomy، حيث يُظهر عملية لا تتطلب إذن المحفظة لتفويض الوكيل الذكي لتبديل ETH بـ USDC.
الذكاء الاصطناعي وأمان المعاملات على السلسلة
في عالم Web3 ، أمان المعاملات على السلسلة حاسم. يمكن استخدام تكنولوجيا الذكاء الاصطناعي لتعزيز أمان وحماية الخصوصية للمعاملات على السلسلة، مع سيناريوهات محتملة تشمل:
مراقبة التداول: تقنية البيانات في الوقت الحقيقي تراقب الأنشطة التداول غير الطبيعية، وتوفر بنية تحتية للتنبيه في الوقت الحقيقي للمستخدمين والمنصات.
تحليل المخاطر: مساعدة المنصة في تحليل بيانات سلوك تداول العملاء وتقييم مستوى مخاطرهم.
على سبيل المثال، تستخدم منصة الأمان SeQure للويب3 الذكاء الاصطناعي لاكتشاف ومنع الهجمات الخبيثة والسلوك الاحتيالي وتسرب البيانات، وتوفر آليات مراقبة وتنبيه في الوقت الحقيقي لضمان أمان واستقرار المعاملات على السلسلة. تشمل الأدوات الأمنية المماثلة الأدوات المدعومة بالذكاء الاصطناعي.
ثانيًا، الذكاء الاصطناعي والبنية التحتية على السلسلة
الذكاء الاصطناعي والبيانات على السلسلة
تكنولوجيا الذكاء الاصطناعي تلعب دوراً هاماً في جمع البيانات وتحليلها على السلسلة الرقمية، مثل:
- تحليلات Web3: منصة تحليلات قائمة على الذكاء الاصطناعي تستخدم خوارزميات تعلم الآلة وتنقيب البيانات لجمع ومعالجة وتحليل البيانات on-chain.
- MinMax AI: يوفر أدوات تحليل البيانات على السلسلة الذاتية بناءً على الذكاء الاصطناعي لمساعدة المستخدمين على اكتشاف الفرص والاتجاهات السوقية المحتملة.
- كايتو: منصة بحث Web3 استنادًا إلى محرك البحث LLM.
- متكامل مع ChatGPT، يجمع ويدمج المعلومات ذات الصلة المبعثرة عبر مواقع الويب المختلفة ومنصات المجتمع للعرض.
- سيناريو تطبيق آخر هو الأوراق المالية، يمكن للذكاء الاصطناعي الحصول على الأسعار من مصادر متعددة لتوفير بيانات تسعير دقيقة. على سبيل المثال، يستخدم Upshot الذكاء الاصطناعي لتقييم الأسعار العابرة للحدود للـ NFTs، وتوفير خطأ نسبي يتراوح بين 3-10% من خلال أكثر من مائة مليون تقييم في الساعة.
الذكاء الاصطناعي والتطوير والتدقيق
مؤخرًا، جذب محرر AI للرموز البرمجية Web2، Cursor، الكثير من الاهتمام في مجتمع المطورين. على منصته، يحتاج المستخدمون فقط إلى وصف باللغة الطبيعية، ويمكن لـ Cursor توليد رمز HTML و CSS و JavaScript تلقائيًا، مما يبسط بشكل كبير عملية تطوير البرمجيات. تنطبق هذه المنطقة أيضًا على تحسين كفاءة تطوير Web3.
حاليًا، يتطلب نشر العقود الذكية وتطبيقات DApps على السلاسل العامة عادة اتباع لغات تطوير حصرية مثل Solidity وRust وMove وما إلى ذلك. رؤية لغات التطوير الجديدة هي توسيع مساحة التصميم لسلاسل الكتل اللامركزية، مما يجعلها أكثر ملاءمة لتطوير تطبيقات DApp. ومع ذلك، نظرًا لنقص المبرمجين في Web3 بشكل كبير، فإن تعليم المطورين كان دائمًا مشكلة أكثر تحديًا.
حاليًا ، يمكن تخيل سيناريوهات استخدام الذكاء الاصطناعي في مساعدة تطوير Web3 بما في ذلك: توليد الشيفرة التلقائي ، والتحقق واختبار العقود الذكية ، ونشر وصيانة تطبيقات اللامركزية ، وإكمال الشيفرة بشكل ذكي ، والإجابة على الحوارات الصعبة حول قضايا التطوير ، وما إلى ذلك. بفضل مساعدة الذكاء الاصطناعي ، فإنه لا يساعد فقط في تحسين كفاءة التطوير والدقة ، ولكنه أيضًا يقلل من عتبة البرمجة ، مما يتيح لغير المبرمجين تحويل أفكارهم إلى تطبيقات عملية ، مما يجلب نشاطًا جديدًا إلى تطوير التكنولوجيا اللامركزية.
حاليا، الأكثر جذبا هو منصة إطلاق رمز بنقرة واحدة، مثل Clanker، وهو 'Token Bot' مدفوع بالذكاء الاصطناعي مصمم لنشر رموز DIY بشكل سريع. كل ما عليك فعله هو وسم Clanker على بروتوكول SocialFi Farcaster العميل مثل Warpcast أو Supercast، وأخبره بفكرة الرمز الخاص بك، وسيقوم بإطلاق الرمز لك على سلسلة الكتل العامة Base.
هناك أيضًا منصات تطوير العقود مثل Spectral التي توفر وظائف توليد ونشر بنقرة واحدة للعقود الذكية لتقليل عتبة تطوير Web3، مما يسمح حتى للمستخدمين المبتدئين بتجميع ونشر العقود الذكية.
من حيث التدقيق، تستخدم منصة التدقيق Web3 Fuzzland الذكاء الاصطناعي لمساعدة المدققين في التحقق من ثغرات الشفرة، وتوفر تفسيرات باللغة الطبيعية لمساعدة المحترفين في التدقيق. تستخدم Fuzzland أيضًا الذكاء الاصطناعي لتوفير تفسيرات باللغة الطبيعية للمواصفات الرسمية وشفرة العقد، بالإضافة إلى بعض الشفرات العينية لمساعدة المطورين في فهم المشاكل المحتملة في الشفرة.
ثلاثة، الذكاء الاصطناعي و الرؤية الثالثة الجديدة
ارتفاع الذكاء الاصطناعي الانشائي يجلب إمكانيات جديدة للسرد الجديد للويب3.
NFT: يضخ الذكاء الاصطناعي الإبداع في NFTs التوليدية. من خلال تقنية الذكاء الاصطناعي ، يمكن إنشاء العديد من الأعمال الفنية والشخصيات الفريدة والمتنوعة. يمكن أن تصبح NFTs التوليدية هذه شخصيات أو دعائم أو عناصر مشهد في الألعاب أو العوالم الافتراضية أو metaverses ، مثل Bicasso ضمن Binance ، حيث يمكن للمستخدمين إنشاء NFTs عن طريق تحميل الصور وإدخال الكلمات الرئيسية لحساب الذكاء الاصطناعي. تشمل المشاريع المماثلة Solvo و Nicho و IgmnAI و CharacterGPT.
GameFi: مع توليد اللغة الطبيعية وتوليد الصور وقدرات NPC الذكية حول الذكاء الاصطناعي، من المتوقع أن يحسن GameFi الكفاءة والابتكار في إنتاج محتوى الألعاب. على سبيل المثال، يسمح اللعبة السلسلة الأولى من Binaryx AI Hero للاعبين باستكشاف خيارات القصة المختلفة من خلال العشوائية الذكاء الاصطناعي؛ وبالمثل، هناك لعبة رفيق الافتراضي Sleepless AI، حيث يمكن للاعبين فتح أسلوب اللعب الشخصي من خلال تفاعلات مختلفة استنادًا إلى AIGC وLLM.
DAO: حاليا ، من المتصور أيضا تطبيق الذكاء الاصطناعي على DAOs ، مما يساعد على تتبع تفاعلات المجتمع ، وتسجيل المساهمات ، ومكافأة الأعضاء الأكثر مساهمة ، والتصويت بالوكالة ، وما إلى ذلك. على سبيل المثال ، يستخدم ai16z وكيل الذكاء الاصطناعي لجمع معلومات السوق على السلسلة وخارجها ، وتحليل إجماع المجتمع ، واتخاذ قرارات الاستثمار جنبا إلى جنب مع اقتراحات من أعضاء DAO.
أهمية تكامل AI+Web3: Tower and Square
في قلب فلورنسا، إيطاليا، تقع الساحة المركزية، المكان الأكثر أهمية للتجمعات السياسية للسكان المحليين والسياح. وفي هذا المكان يقف برج بلدية يبلغ ارتفاعه 95 مترًا، مما يخلق تأثير جمالي درامي مع الساحة، ملهمًا البروفيسور التاريخي في جامعة هارفارد نيل فيرغسون لاستكشاف تاريخ الشبكات والتسلسل الهرمي في كتابه 'الساحة والبرج'، مُظهرًا تقلب الاثنين مع مرور الوقت.
هذه الاستعارة الممتازة لا تخرج عن السياق عند تطبيقها على العلاقة بين الذكاء الاصطناعي والويب3 اليوم. عند النظر إلى العلاقة التاريخية غير الخطية طويلة المدى بين الاثنين، يمكن رؤية أن المربعات أكثر احتمالاً لإنتاج أشياء جديدة ومبتكرة من الأبراج، ولكن لا تزال الأبراج لها شرعية وحيوية قوية.
مع القدرة على تجميع بيانات طاقة الحوسبة في شركات التكنولوجيا، أطلقت الذكاء الاصطناعي خيالًا غير مسبوق، مما دفع العمالقة التكنولوجيين الكبار إلى القيام برهانات ثقيلة، واقتحام عدة تطويرات من الروبوتات الدردشة المختلفة إلى "النماذج الكبيرة الأساسية" مثل GPT-4، GP4-4o. ظهرت روبوتات البرمجة التلقائية (ديفين) وسورا، مع قدرات أولية لمحاكاة العالم الفيزيائي الحقيقي، وظهرت تلو الأخرى، مكبرة خيال الذكاء الاصطناعي لا نهاية له.
في الوقت نفسه، الذكاء الاصطناعي في جوهره صناعة كبيرة الحجم ومركزية، وسيدفع هذه الثورة التكنولوجية الشركات التكنولوجية التي اكتسبت تدريجياً السيطرة الهيكلية في 'عصر الإنترنت' إلى نقطة عالية أضيق. القوة الهائلة، التدفق النقدي الاحتكاري، والمجموعات الضخمة من البيانات المطلوبة للسيطرة على عصر الذكاء تشكل حواجز أعلى لها.
مع نمو البرج وتقلص صانعي القرار خلف الكواليس، تجلب تمركز الذكاء الاصطناعي العديد من المخاطر الخفية. كيف يمكن للجماهير المتجمعة في الساحة تجنب الظلال تحت البرج؟ هذه هي المسألة التي يأمل Web3 في معالجتها.
أساسا، تعزز الخصائص الجوهرية للبلوكشين أنظمة الذكاء الاصطناعي وتجلب إمكانيات جديدة، بشكل رئيسي:
- في عصر الذكاء الاصطناعي، 'الكود هو القانون' - تحقيق قواعد تنفيذ النظام الشفاف من خلال العقود الذكية والتحقق من التشفير، وتقديم مكافآت للجماهير أقرب إلى الهدف.
- اقتصاد الرموز - إنشاء وتنسيق سلوك المشاركين من خلال آلية الرموز، الرهان، الحد من الإمداد، مكافآت الرموز والعقوبات.
- الحكم اللامركزي - يدفعنا إلى التساؤل عن مصادر المعلومات ويشجعنا على نهج أكثر نقدًا وتحليلًا لتقنية الذكاء الاصطناعي، مما يمنع التحيز والمعلومات الخاطئة والتلاعب، ويعزز في النهاية تنمية مجتمع مستنير وممكن بشكل أفضل.
تطوير الذكاء الاصطناعي أحضر أيضًا حيوية جديدة لـ Web3، ربما يحتاج تأثير Web3 على الذكاء الاصطناعي وقتًا للإثبات، ولكن تأثير الذكاء الاصطناعي على Web3 فوري: سواء كانت الجنون من Meme أو الوكيل الذكي الذي يساعد في خفض حاجز الدخول لتطبيقات السلسلة الرقمية، كل ذلك واضح.
عندما يُعرف Web3 بأنه تناول ذاتي من قبل مجموعة صغيرة من الأشخاص، فضلاً عن أن يكونوا محاصرين في شكوك حول تكرار الصناعات التقليدية، فإن إضافة الذكاء الاصطناعي تجلب مستقبل متوقع: قاعدة مستخدمي Web2 أكثر استقرارًا وقابلية للتوسيع، ونماذج أعمال أكثر ابتكارًا، وخدمات.
نعيش في عالم حيث 'الأبراج والساحات' تتعايش، على الرغم من أن الذكاء الاصطناعي والويب3 لديهما أجداول زمنية ونقاط بداية مختلفة، إلا أن هدفهما النهائي هو كيفية جعل الآلات تخدم الإنسانية بشكل أفضل، ولا أحد يمكنه تحديد نهر جاري. نحن نتطلع إلى رؤية مستقبل الذكاء الاصطناعي+الويب3.
بيان:
- تم نقل هذه المقالة من [ تيكفلو]، حقوق النسخ ملك للكاتب الأصلي [Coinspire]، 如对转载有异议,请联系فريق Gate Learn, سيقوم الفريق بمعالجته في أقرب وقت ممكن وفقًا للإجراءات ذات الصلة.
- إخلاء المسؤولية: الآراء والآراء الواردة في هذه المقالة هي فقط تلك التي تعود إلى المؤلف ولا تشكل أي نصيحة استثمارية.
- يتم ترجمة المقال إلى لغات أخرى من قبل فريق بوابة التعلم، إذا لم يُذكرGate.ioتحت أي ظرف من الظروف يجوز نسخ المقالات المترجمة أو توزيعها أو ارتكاب الانتحال.
المقالات ذات الصلة

ما هو Tronscan وكيف يمكنك استخدامه في عام 2025؟

كل ما تريد معرفته عن Blockchain

ما هي كوساما؟ كل ما تريد معرفته عن KSM

ما هو كوتي؟ كل ما تحتاج إلى معرفته عن COTI

ما هي ترون؟
