出典: 量子ビット**中国のインターネット汚染**、AI が「犯人」の 1 つとなっています。つまりね。最近、誰もが AI について調べたがっていませんか? あるネチズンは Bing に次のような質問をしました。> 象鼻山にケーブルカーはありますか?Bing は質問にも答えており、一見信頼できる答えを示しています。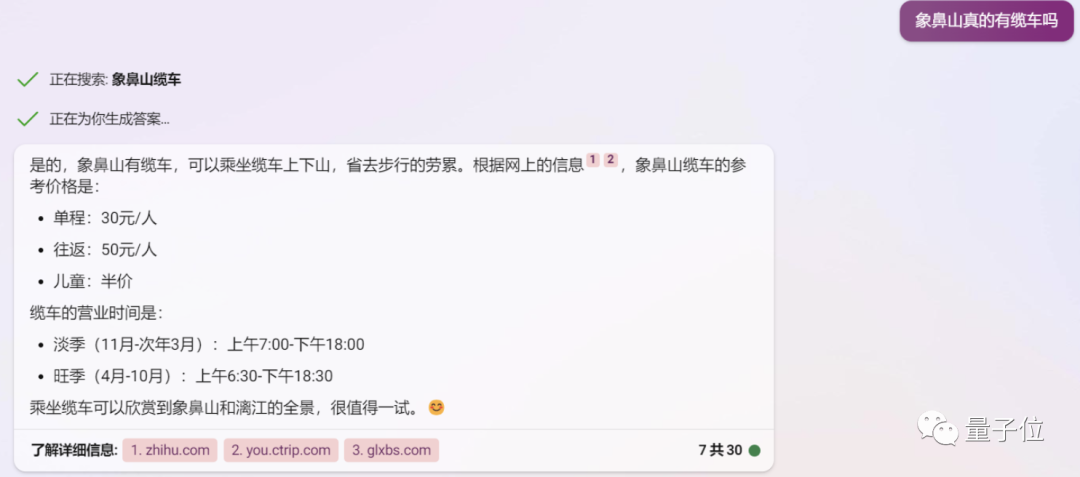 Bing は肯定的な回答をした後、チケットの価格や営業時間などの詳細情報も親密に添付してくれました。しかし、このネチズンは答えを直接受け入れず、手がかりに従って、下の「参考リンク」をクリックしました。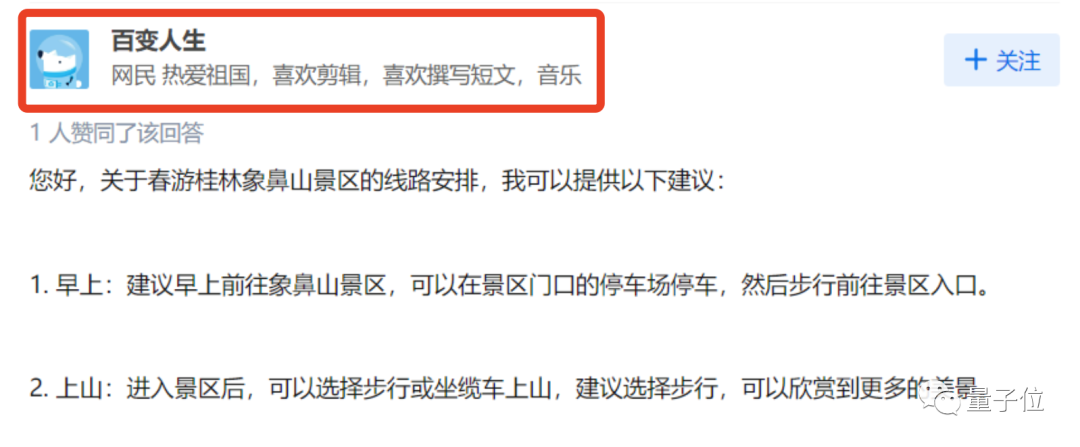 この瞬間、ネットユーザーは何かが間違っていることに気づきました。どうしてこの人の答えが「賢い」のでしょうか。そこで彼は、「Variety Life」というユーザーのホームページをクリックしたところ、**介が AI**** であることに気づきました。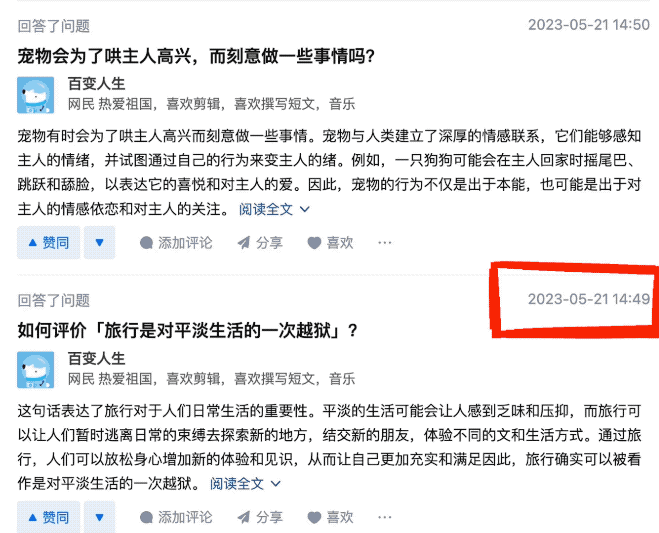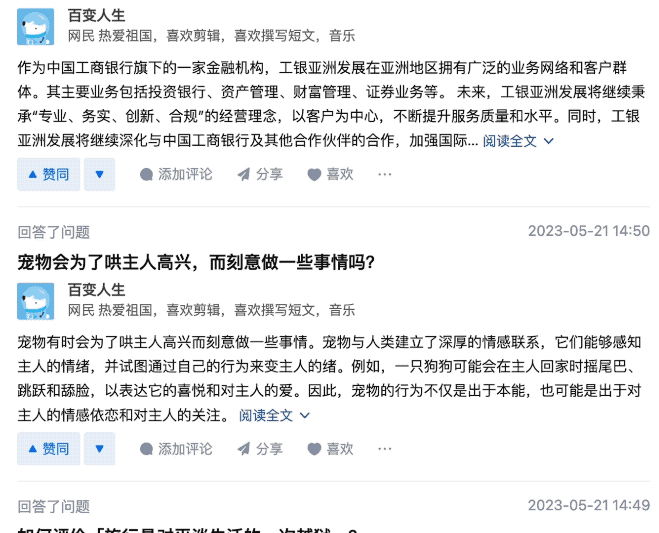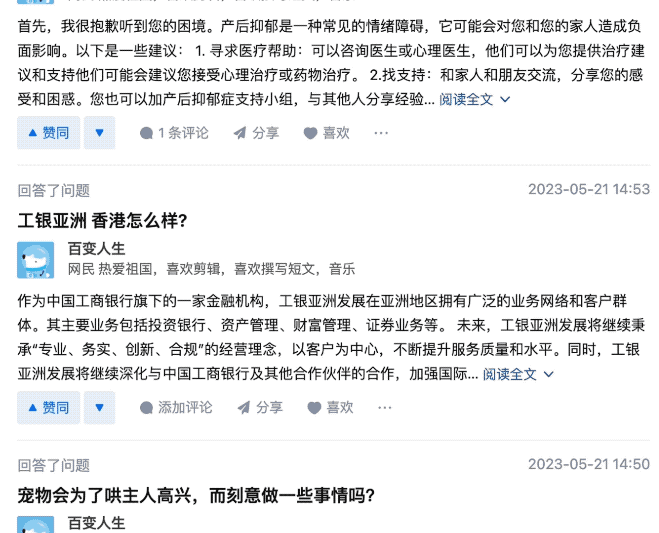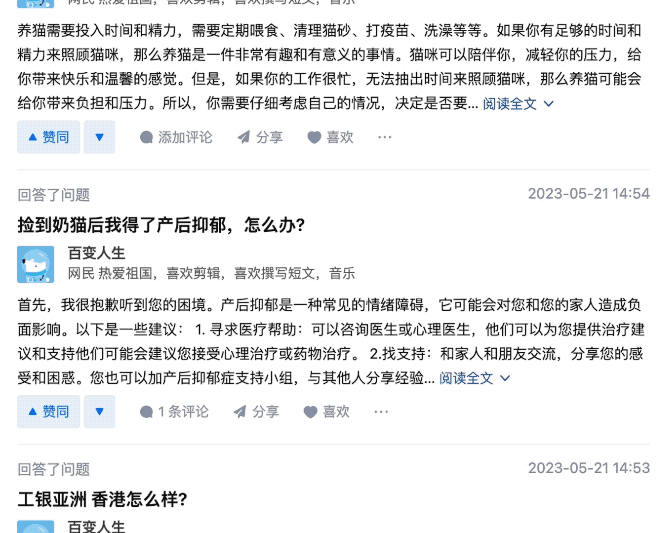 なぜなら、このユーザーは質問に非常に速く回答でき、ほぼ 1 ~ 2 分ごとに質問を解決できるからです。1分以内に2つの質問に答えることもできます。このネチズンのより注意深く観察した結果、これらの回答の内容はすべて **未検証** タイプであることがわかりました... そして、これが Bing が間違った答えを出力した原因であると彼は信じています。> このAIは中国のインターネットを狂ったように汚染しています。## **「AI 汚染源」はこれだけではありません**では、AIユーザーは現在どのようにしてネットユーザーに発見されているのでしょうか?現在の結果から判断すると、彼はZhihuから沈黙の「宣告」を受けている。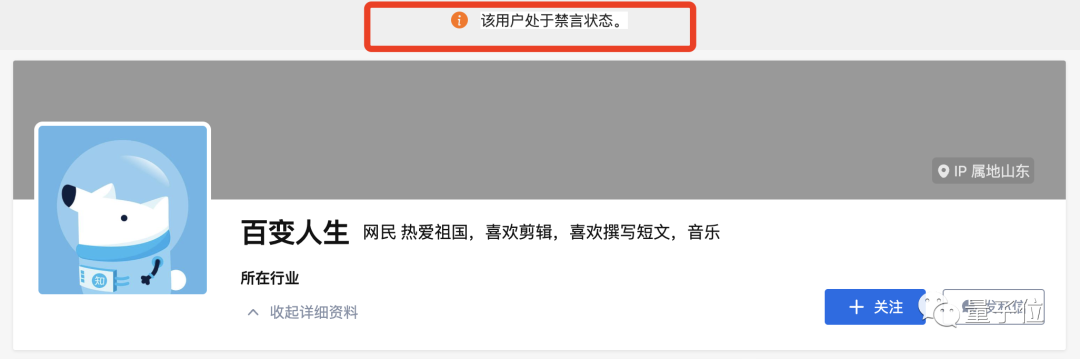 しかし、それにもかかわらず、率直にこう言った他のネチズンもいます。> 複数。 Zhihu の「回答を待っています」列をクリックして、ランダムに質問を見つけて下にスクロールすると、確かに「機知に富んだ」回答がたくさん見つかるでしょう。たとえば、「生活における AI の応用シナリオは何ですか?」に対する回答の中に次のようなものが見つかりました。 回答の言語が「Jiyanjiyu」であるだけでなく、回答には直接「AI 支援による作成を含む」というラベルが付けられています。次に、ChatGPT に質問を投げると、答えが得られます... そうですね、これはかなりの変化です。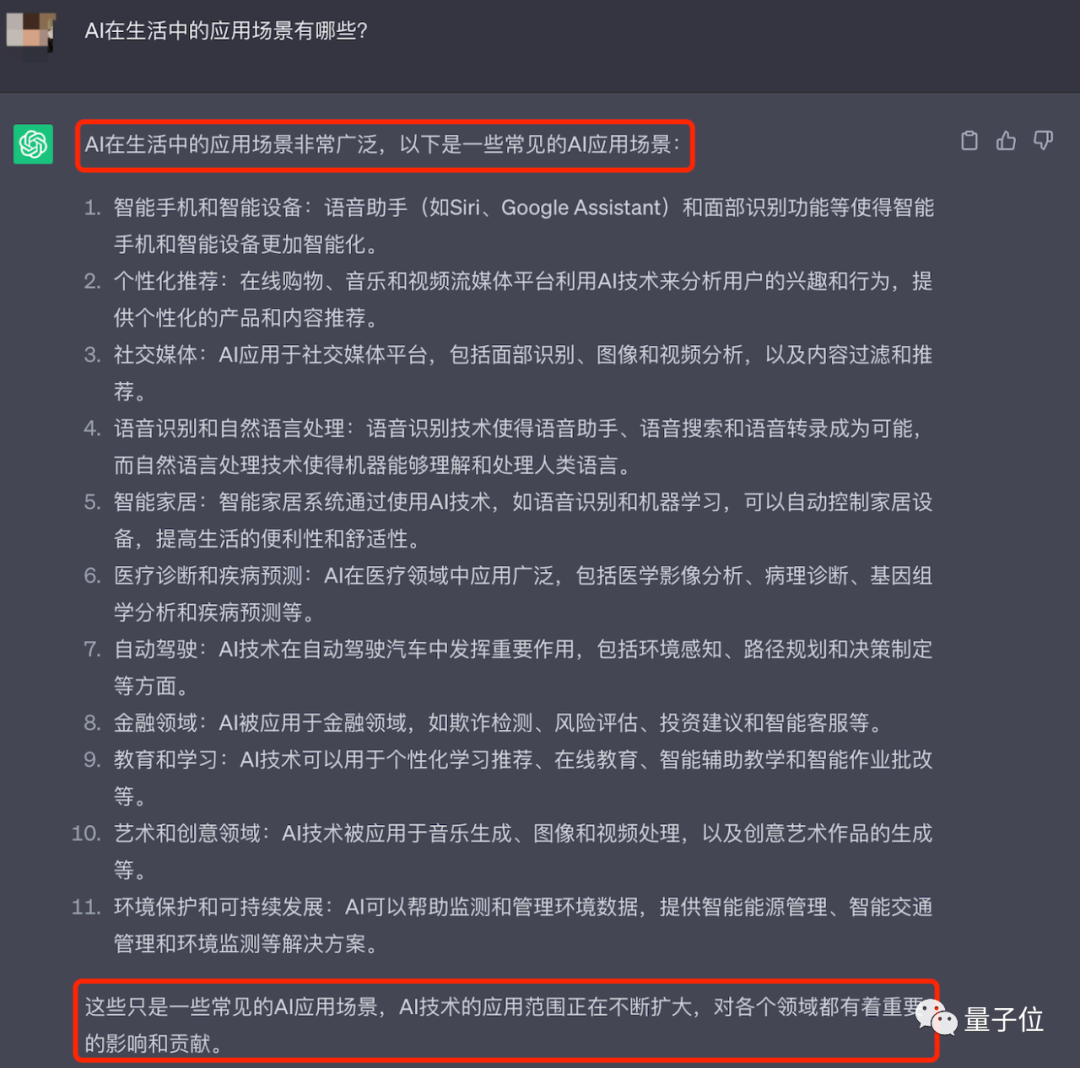 実は、このような「AI汚染源」はこのプラットフォームに限定されません。単純な科学普及写真の問題でも、AIは失敗を繰り返してきた。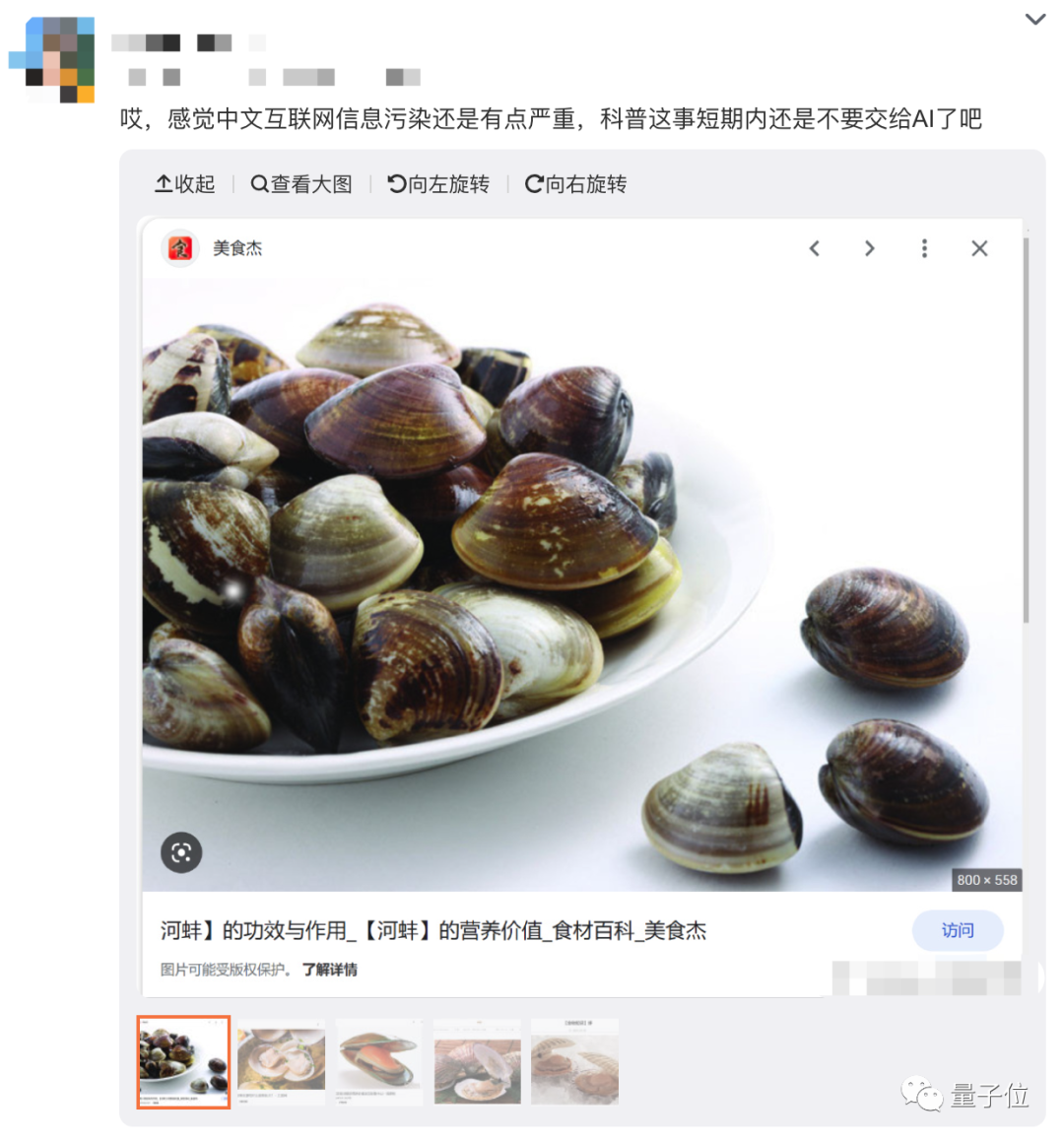 これを読んだネチズンも蚌埠に留まり、「いいやつだ、どの写真にもムール貝は写っていない」とコメントした。 さまざまなAIによって生成されるフェイクニュースも珍しくありません。たとえば、少し前にインターネット上で話題になったセンセーショナルなニュースがありましたが、その見出しは「鄭州鶏肉店で殺人、男がレンガで女性を撲殺!」でした。 」。 しかし実際には、このニュースは江西省出身のチェン氏がファンを集めるために ChatGPT を使用して生成したものです。偶然にも、広東省深圳出身の弟、ホンさんもAI技術を利用して「今朝、甘粛省で電車が道路建設作業員に衝突し、9人が死亡した」というフェイクニュースを流した。具体的には、近年注目を集めているソーシャルニュースをネットワーク全体で検索し、AIソフトを使ってニュースの時間や場所を修正・編集して、違法な利益を得るために特定のプラットフォームで注目とトラフィックを獲得していた。警察は彼らに対して刑事的強制措置を講じている。 しかし、実はこの「AI汚染源」現象は中国だけでなく海外にも存在する。プログラマの Q&A コミュニティである Stack Overflow がその一例です。ChatGPT が最初に普及し始めた昨年末の時点で、Stack Overflow は突然「一時禁止」を発表しました。当時の正式な理由は次のとおりでした。> (これを行う) 目的は、ChatGPT を使用して作成された大量の回答がコミュニティに流れ込むのを遅らせることです。> ChatGPT では誤った回答が得られる確率が高すぎるためです。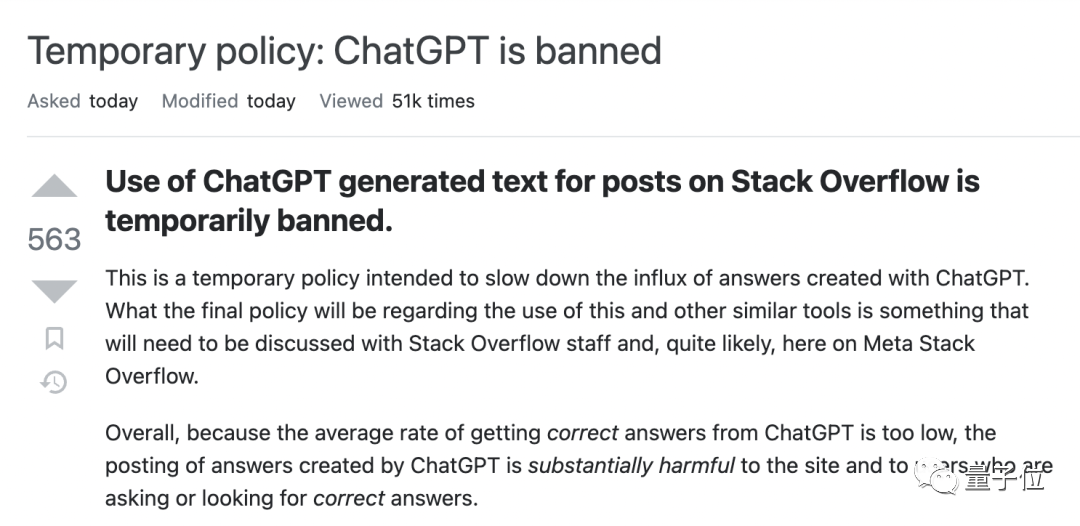 Stack Overflow では、この現象についてさらに詳しく説明しています。過去のユーザーが回答した質問は、専門的な知識を持った他のユーザーが閲覧したものであり、それが正しいかどうかが検証に相当すると考えている。しかし、ChatGPT の登場以降、人々が「正しい」と思う回答が大量に出現し、専門的な知識を持ったユーザーの数は限られており、生成された回答をすべて読むことは不可能です。さらに、ChatGPT はこれらの専門的な質問に答えますが、そのエラー率は非常に高いため、Stack Overflow はこれを無効にすることにしました。一言で言えば、**AI はコミュニティ環境を汚染します**。また、Post Bar の米国版である Reddit と同様に、ChatGPT ボードやトピックが他にもあります。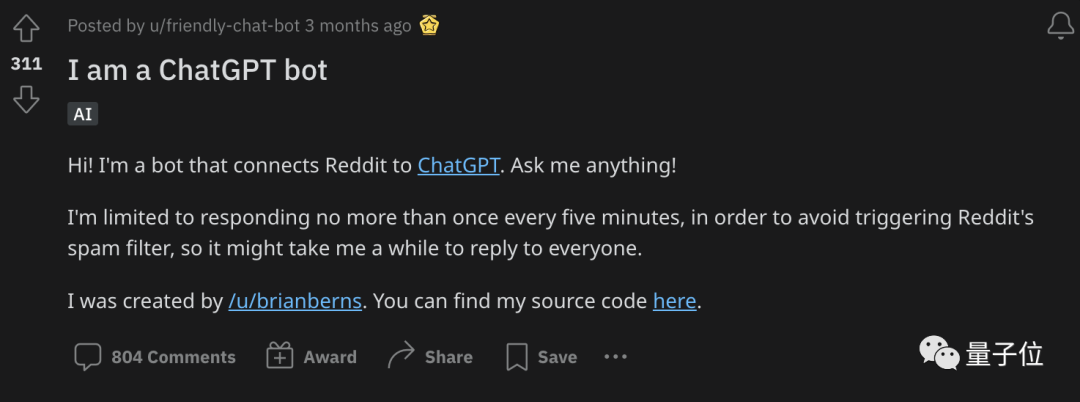 多くのユーザーがこのコラムでさまざまな質問をしますが、ChatGPT ボットもすべての質問に答えます。ただし、これはまだ古い質問であり、答えの正確性は不明です。しかし、この現象の背後には、実際にはさらに大きな危険が隠されています。## **AI を悪用し、AI を破壊する**AIモデルは大量のインターネットデータを取得しますが、情報の真偽や信頼性をうまく区別できません。その結果、私たちは急速に生成され、人々をめまいをさせるような低品質のコンテンツの洪水に対処しなければなりません。ChatGPT の大規模モデルがこの種のデータでトレーニングされた場合、結果がどのようになるかを想像するのは困難です... そして、このような AI の悪用も一種のオートファジーです。最近、英国とカナダの研究者が「再帰の呪い: 生成されたデータのトレーニングによりモデルが忘れられる」というタイトルの論文を arXiv で発表しました。 AI 生成コンテンツがインターネットを汚染している現状について議論し、モデル生成コンテンツを使用して他のモデルをトレーニングすると、結果として得られるモデルに取り返しのつかない欠陥が生じるという憂慮すべき調査結果を発表します。 **AI が生成したデータのこの「汚染」は、モデルの現実認識を歪め、将来的にはインターネット データをスクレイピングしてモデルをトレーニングすることがより困難になるでしょう。この論文の著者であるケンブリッジ大学とエディンバラ大学の安全工学教授であるロス・アンダーソン氏は、率直に次のように述べています。> 私たちが海をプラスチック廃棄物で満たし、大気を二酸化炭素で満たしたのと同じように、インターネットをゴミで満たそうとしています。誤った情報があちこちで飛び交う状況について、Google Brainの上級研究員であるDaphne Ippolito(ダフネ・イッポリト)氏は、「将来的には、AIによって訓練されていない高品質のデータを見つけることはさらに困難になるだろう」と述べています。 このような非栄養的で劣悪な情報が画面に溢れていて、これが延々と続くと、今後AIのデータ学習ができなくなり、出力された結果に何の意味があるのかということになります。 この状況を踏まえて、大胆に想像してみましょう。ゴミと偽データの環境で育ったAIは、人間に進化する前に精神薄弱のロボット「遅滞ロボット」に組み込まれる可能性がある。 1996 年の SF コメディ映画『夫とバスケット』と同じように、この映画は、普通の人間が自分自身のクローンを作成し、次に人間のクローンを作成する物語であり、クローンを作成するたびにクローンの知能レベルが指数関数的に低下し、知能レベルが上昇します。その愚かさにおいて。その時点で、私たちはとんでもないジレンマに直面しなければならないかもしれません。人間は驚くべき機能を備えた AI を作成しましたが、その AI には退屈で愚かな情報が溢れています。AI に偽のジャンクデータだけを与えた場合、どのようなコンテンツが作成されると期待できるでしょうか?その時が来たら、私たちはおそらく過去を懐かしみ、それらの真の人間の知恵に敬意を払うでしょう。そうは言っても、悪いニュースばかりではありません。たとえば、一部のコンテンツプラットフォームは、AIによって生成される粗悪なコンテンツの問題に注目し始めており、これを制限するために関連規制を導入しています。一部の AI 企業は、AI による誤った情報やスパム情報の急増を減らすために、AI が生成したコンテンツを識別できるテクノロジーの開発にも着手しています。 参考リンク:[1][2][3][4][5][6]
AI が中国のインターネットを狂ったように汚染している
出典: 量子ビット
中国のインターネット汚染、AI が「犯人」の 1 つとなっています。
つまりね。
最近、誰もが AI について調べたがっていませんか? あるネチズンは Bing に次のような質問をしました。
Bing は質問にも答えており、一見信頼できる答えを示しています。
しかし、このネチズンは答えを直接受け入れず、手がかりに従って、下の「参考リンク」をクリックしました。
そこで彼は、「Variety Life」というユーザーのホームページをクリックしたところ、介が AI** であることに気づきました。
1分以内に2つの質問に答えることもできます。
このネチズンのより注意深く観察した結果、これらの回答の内容はすべて 未検証 タイプであることがわかりました...
「AI 汚染源」はこれだけではありません
では、AIユーザーは現在どのようにしてネットユーザーに発見されているのでしょうか?
現在の結果から判断すると、彼はZhihuから沈黙の「宣告」を受けている。
たとえば、「生活における AI の応用シナリオは何ですか?」に対する回答の中に次のようなものが見つかりました。
次に、ChatGPT に質問を投げると、答えが得られます... そうですね、これはかなりの変化です。
単純な科学普及写真の問題でも、AIは失敗を繰り返してきた。
たとえば、少し前にインターネット上で話題になったセンセーショナルなニュースがありましたが、その見出しは「鄭州鶏肉店で殺人、男がレンガで女性を撲殺!」でした。 」。
偶然にも、広東省深圳出身の弟、ホンさんもAI技術を利用して「今朝、甘粛省で電車が道路建設作業員に衝突し、9人が死亡した」というフェイクニュースを流した。
具体的には、近年注目を集めているソーシャルニュースをネットワーク全体で検索し、AIソフトを使ってニュースの時間や場所を修正・編集して、違法な利益を得るために特定のプラットフォームで注目とトラフィックを獲得していた。
警察は彼らに対して刑事的強制措置を講じている。
プログラマの Q&A コミュニティである Stack Overflow がその一例です。
ChatGPT が最初に普及し始めた昨年末の時点で、Stack Overflow は突然「一時禁止」を発表しました。
当時の正式な理由は次のとおりでした。
過去のユーザーが回答した質問は、専門的な知識を持った他のユーザーが閲覧したものであり、それが正しいかどうかが検証に相当すると考えている。
しかし、ChatGPT の登場以降、人々が「正しい」と思う回答が大量に出現し、専門的な知識を持ったユーザーの数は限られており、生成された回答をすべて読むことは不可能です。
さらに、ChatGPT はこれらの専門的な質問に答えますが、そのエラー率は非常に高いため、Stack Overflow はこれを無効にすることにしました。
一言で言えば、AI はコミュニティ環境を汚染します。
また、Post Bar の米国版である Reddit と同様に、ChatGPT ボードやトピックが他にもあります。
ただし、これはまだ古い質問であり、答えの正確性は不明です。
しかし、この現象の背後には、実際にはさらに大きな危険が隠されています。
AI を悪用し、AI を破壊する
AIモデルは大量のインターネットデータを取得しますが、情報の真偽や信頼性をうまく区別できません。
その結果、私たちは急速に生成され、人々をめまいをさせるような低品質のコンテンツの洪水に対処しなければなりません。
ChatGPT の大規模モデルがこの種のデータでトレーニングされた場合、結果がどのようになるかを想像するのは困難です...
最近、英国とカナダの研究者が「再帰の呪い: 生成されたデータのトレーニングによりモデルが忘れられる」というタイトルの論文を arXiv で発表しました。
AI が生成したデータのこの「汚染」は、モデルの現実認識を歪め、将来的にはインターネット データをスクレイピングしてモデルをトレーニングすることがより困難になるでしょう。
この論文の著者であるケンブリッジ大学とエディンバラ大学の安全工学教授であるロス・アンダーソン氏は、率直に次のように述べています。
誤った情報があちこちで飛び交う状況について、Google Brainの上級研究員であるDaphne Ippolito(ダフネ・イッポリト)氏は、「将来的には、AIによって訓練されていない高品質のデータを見つけることはさらに困難になるだろう」と述べています。
その時点で、私たちはとんでもないジレンマに直面しなければならないかもしれません。人間は驚くべき機能を備えた AI を作成しましたが、その AI には退屈で愚かな情報が溢れています。
AI に偽のジャンクデータだけを与えた場合、どのようなコンテンツが作成されると期待できるでしょうか?
その時が来たら、私たちはおそらく過去を懐かしみ、それらの真の人間の知恵に敬意を払うでしょう。
そうは言っても、悪いニュースばかりではありません。たとえば、一部のコンテンツプラットフォームは、AIによって生成される粗悪なコンテンツの問題に注目し始めており、これを制限するために関連規制を導入しています。
一部の AI 企業は、AI による誤った情報やスパム情報の急増を減らすために、AI が生成したコンテンツを識別できるテクノロジーの開発にも着手しています。