Dados enquanto Ativo: DataFi Está a Criar um Novo Oceano Azul
«Vivemos numa época em que existe uma competição global para desenvolver os principais modelos fundacionais de IA. Embora o poder computacional e a arquitetura sejam relevantes, a verdadeira vantagem competitiva reside nos dados de treino.»
—Sandeep Chinchali, Chief AI Officer, Story
A Explorar o Potencial do Sector dos Dados de IA: Uma Perspetiva da Scale AI
Uma das grandes notícias deste mês no universo da IA é a demonstração de poder financeiro por parte da Meta, com Mark Zuckerberg a apostar forte na aquisição de talento para criar uma equipa de IA de topo, onde se destacam vários investigadores chineses. No centro deste movimento está Alexander Wang, de 28 anos, fundador da Scale AI. Wang construiu a Scale AI do zero—hoje avaliada em 29 mil milhões de dólares—e serve clientes como as forças armadas dos EUA, além de rivais do setor como a OpenAI, Anthropic e a própria Meta. Todos estes gigantes da IA dependem da Scale AI para serviços de dados, sendo o foco principal da Scale o fornecimento de grandes volumes de dados rotulados e de alta qualidade.
Porque é que a Scale AI se destacou como unicórnio?
O segredo está na perceção precoce do papel fundamental dos dados na indústria da IA.
Computação, modelos e dados formam os três pilares essenciais da pilha da IA. Imagine o modelo como o corpo, a computação como alimento e os dados como conhecimento e experiência acumulados.
Com a ascensão dos grandes modelos de linguagem, as prioridades da indústria passaram da arquitetura dos modelos para a infraestrutura computacional. Os principais modelos optaram pelos transformers como padrão, com inovações como MoE ou MoRe. As grandes entidades ou desenvolvem as suas próprias infraestruturas de computação ou celebram contratos de longa duração com fornecedores de cloud de hiperescala como a AWS. Com a questão computacional resolvida, a atenção vira-se agora para o papel crucial dos dados.
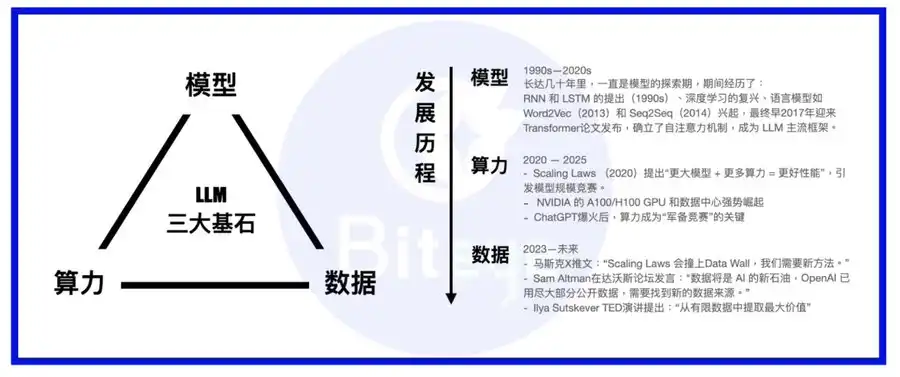
Ao contrário de empresas de dados empresariais estabelecidas, como a Palantir, a Scale AI concentra-se em construir uma base de dados robusta dedicada à IA. O seu negócio vai muito além da mera extração de dados existentes; aposta na geração contínua de dados, reunindo equipas de especialistas humanos para garantir dados de treino de qualidade superior aos modelos de IA.
Ainda com dúvidas sobre este negócio? Veja como se treinam os modelos.
O treino de um modelo de IA decorre em duas fases—pré-treino e afinação.
O pré-treino assemelha-se à aprendizagem da fala por um bebé: a IA absorve grandes volumes de texto e código da internet para adquirir linguagem natural e bases de comunicação.
A afinação corresponde à educação formal, onde há respostas certas e erradas. Tal como o currículo escolar molda os estudantes, também utilizamos conjuntos de dados concebidos e preparados para dotar os modelos de competências específicas.

Neste ponto, torna-se claro que são necessários ambos os tipos de dados:
· Um tipo exige processamento mínimo—o fator crítico é a quantidade. Tipicamente, trata-se de dados extraídos de grandes plataformas de conteúdos gerados por utilizadores (Reddit, Twitter), repositórios abertos ou bases de dados empresariais privadas.
· O outro tem a natureza de um manual especializado—dados criteriosamente selecionados e desenhados para transmitir capacidades específicas. Este grupo envolve limpeza, filtragem, rotulagem e validação humana.
Em conjunto, estes dois tipos constituem o suporte essencial do mercado de dados para IA. Embora tecnicamente os conjuntos de dados possam parecer simples, a visão predominante é que, à medida que as leis de escalabilidade computacional chegam ao limite, os dados tornar-se-ão o fator crítico de diferenciação para os grandes fornecedores de modelos.
À medida que os modelos evoluem, dados de treino cada vez mais refinados e específicos serão o ingrediente principal para maximizar o desempenho. No mesmo paralelo, se treinar modelos for como preparar um mestre de artes marciais, os dados são o manual de treino de excelência—a computação, o elixir mágico; e o modelo, o talento inato.
Do ponto de vista vertical, os dados de IA configuram-se como um setor de crescimento composto a longo prazo. O trabalho inicial acumula-se e os ativos de dados geram retornos crescentes, adquirindo mais valor ao longo do tempo.
Web3 DataFi: O Terreno de Cultivo Ideal para Dados de IA
Em comparação com a vasta rede de colaboradores remotos da Scale AI em países como Filipinas e Venezuela, o Web3 conta com vantagens próprias no universo dos dados de IA—dando origem ao conceito de DataFi.
As vantagens ideais do DataFi Web3 são:
1. Propriedade, Segurança e Privacidade de Dados asseguradas por Contratos Inteligentes
Com os dados públicos praticamente esgotados, obter dados inéditos, incluindo privados, tornou-se decisivo. Surge então a questão da confiança: vender os seus dados a um agregador central, ou manter a sua propriedade intelectual na blockchain, garantindo o controlo e transparência sobre quem usa os seus dados, quando e para quê graças a contratos inteligentes?
Para informação sensível, tecnologias como provas de conhecimento zero (zero-knowledge proofs) e hardware TEE (Trusted Execution Environment) asseguram que apenas máquinas têm acesso, protegendo a privacidade e prevenindo fugas.
2. Arbitragem Geográfica Nativa: Participação Distribuída e Acesso ao Melhor Talento Global
Está na altura de repensar os modelos de trabalho tradicionais. Em vez de uma busca global centralizada por mão-de-obra barata, como faz a Scale AI, o design descentralizado do Web3—assente em incentivos claros via contratos inteligentes—permite que pessoas em todo o mundo contribuam com dados e sejam justamente remuneradas.
Para tarefas como rotulagem ou validação de modelos, esta abordagem distribuída incentiva a diversidade e minimiza o viés—crucial para assegurar dados de qualidade.
3. Incentivos e Liquidações Transparentes com Blockchain
Para evitar operações pouco fiáveis, os contratos inteligentes da blockchain garantem incentivos abertos e automáticos—superando sistemas manuais opacos.
À medida que a globalização desacelera, recorrer à arbitragem geográfica através da criação de empresas em múltiplos mercados torna-se cada vez mais difícil. A liquidação on-chain contorna essas barreiras e simplifica a participação e remuneração transfronteiriça.
4. Marketplaces de Dados Eficientes, Abertos e Directos
Os intermediários continuam a ser uma dor de cabeça recorrente. Em vez de recorrer a empresas de dados centralizadas, plataformas on-chain podem operar como marketplaces transparentes, ao estilo Taobao, ligando diretamente compradores e vendedores para máxima eficiência.
A procura por dados de IA on-chain vai tornar-se cada vez mais segmentada e complexa, e só um marketplace descentralizado pode dar resposta eficiente e rentável a esta nova realidade, em escala.
DataFi: O Caminho Mais Acessível à IA Descentralizada para o Utilizador Individual
Apesar de os instrumentos de IA facilitarem o acesso e a IA descentralizada prometer romper com os monopólios tradicionais, muitos projetos continuam inacessíveis ao utilizador não técnico. Participar em redes de computação descentralizada exige hardware dispendioso, e os marketplaces de modelos podem ser intimidantes.
O Web3, pelo contrário, abre portas inéditas para qualquer pessoa no universo da IA. Já não é preciso sujeitar-se a contratos laborais exploratórios—basta conectar a sua wallet para participar. Pode fornecer dados, rotular outputs de IA recorrendo à sua intuição, avaliar modelos ou usar ferramentas simples de IA para trabalho criativo ou transações de dados—sem barreira técnica para quem está habituado a airdrops.
Principais Projetos DataFi Web3 a Seguir com Atenção
O investimento dita a tendência. Os 14,3 mil milhões de dólares investidos pela Meta na Scale AI e a valorização cinco vezes superior das ações da Palantir já comprovaram o potencial do DataFi no Web2; no Web3, DataFi destaca-se em captação de investimento. Eis alguns projetos de referência:
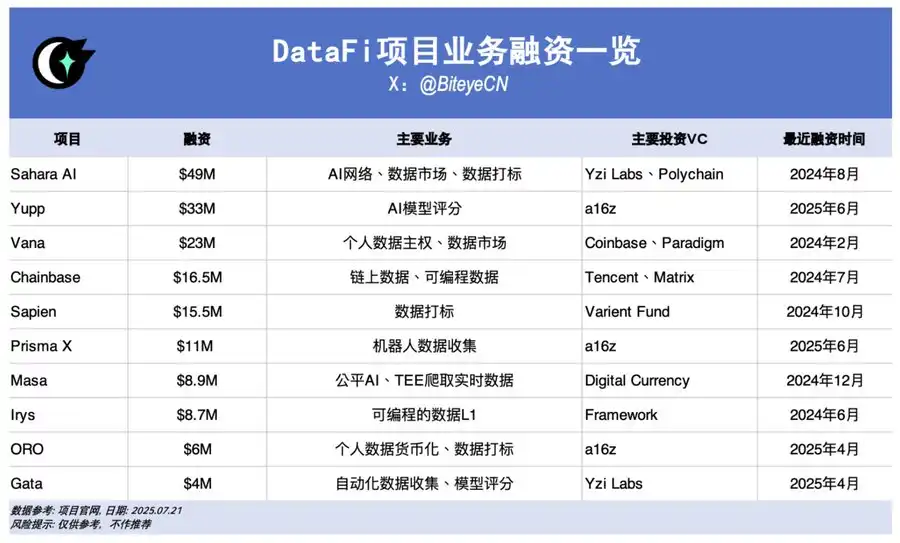
Sahara AI, @SaharaLabsAI, 49 milhões de dólares angariados
O objetivo da Sahara AI é criar uma super-infraestrutura descentralizada de IA e um marketplace de dados. A plataforma Data Services Platform (DSP), atualmente em versão beta, ficará disponível a partir de 22 de julho, recompensando utilizadores por contribuição e rotulagem de dados.
Link: app.saharaai.com
Yupp, @yupp_ai, 33 milhões de dólares angariados
O Yupp é uma plataforma de avaliação de IA que permite aos utilizadores comparar outputs de modelos para o mesmo prompt e votar na melhor opção. Os pontos Yupp obtidos podem ser convertidos em stablecoins como USDC.
Link: https://yupp.ai/
Vana, @vana, 23 milhões de dólares angariados
A Vana permite transformar dados pessoais—como o histórico de navegação e de atividade social—em ativos digitais. Estes dados são agrupados em DataDAOs e Data Liquidity Pools para treino de IA, atribuindo tokens aos participantes.
Link: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, 16,5 milhões de dólares angariados
A Chainbase dedica-se a dados on-chain, estruturando informação de mais de 200 blockchains como ativos monetizáveis para developers de DApps. A indexação e tratamento são assegurados pelo sistema Manuscript e pela Theia AI. A participação de utilizadores de retalho é, para já, limitada.
Sapien, @JoinSapien, 15,5 milhões de dólares angariados
A Sapien converte conhecimento humano em escala em dados de treino premium para IA. Qualquer utilizador pode rotular dados na plataforma, com garantia de qualidade através de revisão pelos pares. Incentiva-se reputação e staking de longo prazo para maximizar recompensas.
Link: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, 11 milhões de dólares angariados
A Prisma X quer ser a camada aberta de coordenação de robôs, tendo a recolha física de dados como pilar central. Ainda em fase inicial, já permite participação em atividades de apoio à recolha de dados robóticos, operação remota, ou quizzes para obter pontos.
Link: https://app.prismax.ai/whitepaper
Masa, @getmasafi, 8,9 milhões de dólares angariados
A Masa lidera o ecossistema Bittensor via sub-redes de dados e agentes. A subnet de dados permite acesso em tempo real através de hardware TEE, recolhendo dados do X/Twitter. No presente, a participação de retalho é cara e complexa.
Irys, @irys_xyz, 8,7 milhões de dólares angariados
Irys providencia armazenamento programável e económico de dados e computação para IA e DApps ricos em dados. As oportunidades de contributo de dados por utilizadores são limitadas, mas a fase de testnet inclui várias atividades de participação.
Link: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, 6 milhões de dólares angariados
A ORO permite a qualquer pessoa contribuir para IA—ligando contas pessoais (sociais, saúde ou fintech) ou completando tarefas de dados. A testnet já se encontra aberta para participação.
Link: app.getoro.xyz
Gata, @Gata_xyz, 4 milhões de dólares angariados
Como camada de dados descentralizada, a Gata disponibiliza atualmente três produtos essenciais: Data Agent (agentes de IA ativados por browser), All-in-one Chat (semelhante ao Yupp, recompensas por avaliação de modelos) e GPT-to-Earn (extensão para browser que recolhe conversas do ChatGPT).
Link: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
Como avaliar estes projetos?
Atualmente, as barreiras técnicas destes projetos são muito baixas, mas a retenção de utilizadores e de ecossistema pode crescer muito rapidamente. Investir cedo em incentivos e experiência de utilizador é crucial: só garantindo escala de utilizadores uma plataforma pode conquistar o mercado dos dados.
Como negócios intensivos em mão-de-obra, as plataformas de dados enfrentam desafios na gestão das equipas e na garantia de qualidade. Muitos projetos Web3 enfrentam o problema recorrente de a maioria dos participantes visar apenas benefícios rápidos—os chamados “farmers”—em detrimento da qualidade. Caso esta tendência persista, maus intervenientes acabarão por afastar colaboradores qualificados, colocando em causa a integridade dos dados e a confiança de potenciais compradores. Sahara, Sapien e outros já priorizam a qualidade dos dados e investem em relações de longo prazo com a sua comunidade.
Outro desafio reside na falta de transparência. A “tríade impossível” do blockchain faz com que muitos projetos nasçam centralizados, mas continuam a exibir caraterísticas Web2, mesmo operando no Web3—com pouca informação on-chain acessível e uma abertura ainda por comprovar. Isso prejudica a saúde de futuro do DataFi. Deseja-se que as equipas preservem o espírito original e acelerem o caminho para abertura e transparência.
Por último, para massificar o DataFi são necessários dois pilares: atrair utilizadores de retalho para alimentar a economia de dados IA, e captar clientes empresariais, que permanecem a principal fonte de receita a curto e médio prazo. Neste âmbito, Sahara AI, Vana e outros projetos têm registado progressos destacados.
Conclusão
Em última análise, o DataFi consiste em potenciar a inteligência humana para fomentar, a longo prazo, a inteligência das máquinas—garantindo, com contratos inteligentes, que as contribuições humanas são recompensadas e, em última instância, permitindo que as pessoas beneficiem do progresso da inteligência artificial.
Para quem sente incerteza perante a nova era da IA, ou mantém confiança na tecnologia blockchain, mesmo perante a volatilidade do mercado das criptomoedas, participar no DataFi poderá ser uma escolha sensata e estratégica.
Aviso Legal:
- Este artigo é uma reprodução de [BLOCKBEATS], com direitos de autor do autor original [anci_hu49074, core contributor da Biteye]. Para questões de reprodução, contacte a Equipa Gate Learn para uma resolução célere, segundo os procedimentos adequados.
- Aviso: As opiniões expressas neste artigo são da exclusiva responsabilidade do autor e não constituem aconselhamento para investimento.
- As versões noutras línguas foram traduzidas pela Equipa Gate Learn. Sem menção específica a Gate, nenhuma tradução pode ser reproduzida, distribuída ou plagiada.
Artigos relacionados

Utilização de Bitcoin (BTC) em El Salvador - Análise do Estado Atual

O que é o Gate Pay?

O que é o BNB?

O que é o USDC?

O que é Coti? Tudo o que precisa saber sobre a COTI
