Данные как актив: DataFi формирует новый рынок с неограниченными возможностями
«Сегодня мы наблюдаем глобальную гонку за создание ведущих базовых моделей искусственного интеллекта. При всей важности вычислительных ресурсов и архитектуры, основной конкурентной защитой становятся именно обучающие данные».
— Сандип Чинчали, директор по искусственному интеллекту, Story
Потенциал рынка данных для ИИ: взгляд Scale AI
Одна из крупнейших новостей месяца в сфере ИИ — демонстрация мощных финансовых ресурсов Meta, где Марк Цукерберг активно формирует лучшую команду Meta AI с привлечением ведущих китайских исследователей. Руководит этим направлением 28-летний Александр Ван, основатель Scale AI, который создал компанию с нуля. Сегодня ее оценка достигает $29 млрд, а среди клиентов — Министерство обороны США и ведущие игроки отрасли: OpenAI, Anthropic, Meta. Все эти гиганты ИИ используют услуги Scale AI по получению масштабных, высококачественных размеченных данных — это и есть основное направление деятельности Scale AI.
Почему Scale AI стал одним из главных единорогов индустрии?
Все дело в раннем понимании ключевой роли данных в индустрии ИИ.
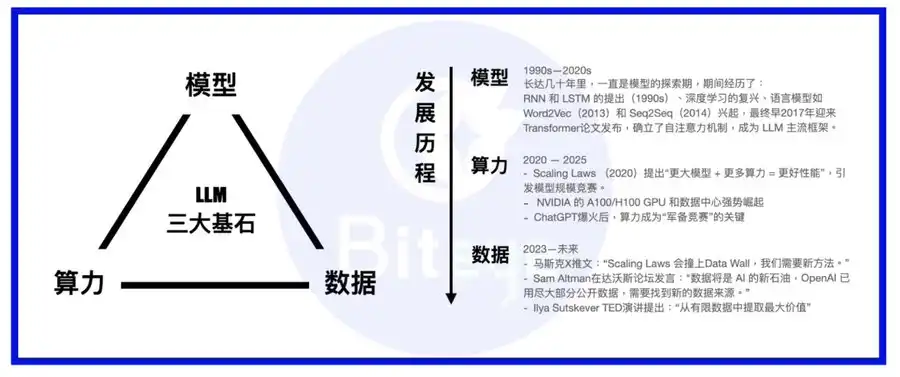
Вычисления, модели, данные — три опоры экосистемы ИИ. Модель — это тело, вычисления — питание, а данные — накопленные знания и опыт.
После появления крупных языковых моделей отрасль сместила фокус с архитектуры модели на инфраструктуру вычислений. Все ведущие решения используют архитектуру трансформеров, периодически появляются технологические инновации — MoE, MoRe. Главные игроки либо создают собственные суперкомпьютерные кластеры, либо заключают долгосрочные соглашения с облачными гигантами вроде AWS. Когда вычислительные ресурсы обеспечены, на первый план выходит вопрос данных.
В отличие от устоявшихся дата-компаний (например, Palantir), Scale AI строит фундаментальную инфраструктуру данных именно под задачи ИИ. Компания не просто перерабатывает имеющиеся наборы, а создает долгосрочные процессы наращивания данных — формируя команды экспертов для поставки максимально качественного обучающего материала.
Не верите в такой бизнес? Давайте разберём, как обучают модели.
Обучение ИИ-модели проходит в два этапа: предобучение и дообучение (fine-tuning).
Предобучение — это как освоение речи младенцем: ИИ «проглатывает» огромные массивы текстов и кода из интернета, чтобы научиться языку и коммуникации.
Файнтюнинг — это формальное образование с чёткими правильными и неправильными ответами: как школа формирует ученика по программе, так и специальные, тщательно подготовленные датасеты позволяют развивать у модели нужные компетенции.

Очевидно: нужны обе категории данных —
· Первая требует минимальной обработки, важен объём. Обычно речь о датасетах, собранных с платформ пользовательского контента (Reddit, Twitter), открытых научных библиотек или закрытых корпоративных источников.
· Вторая подобна специализированным учебникам: тщательно спроектированные и промаркированные данные для передачи уникальных навыков или знаний. Здесь необходимы очистка, фильтрация, разметка и человеческая обратная связь.
Вместе эти группы образуют инфраструктурную основу рынка ИИ-данных. При всех технологических простотах датасетов именно данные становятся ключевым конкурентным преимуществом по мере исчерпания потенциала масштабирования вычислений.
По мере того как ИИ-модели совершенствуются, всё более узкоспециализированные и детализированные обучающие данные становятся факторами роста их качества. Аналогия: если обучение модели — это путь мастера боевых искусств, данные — это лучшее учебное руководство, вычисления — волшебный эликсир, а сама модель — врожденный талант.
С точки зрения вертикали, рынок данных ИИ — это долгосрочная область с накопительным эффектом: чем раньше и шире заложен фундамент, тем дороже и ценнее становятся данные с возрастом.
Web3 DataFi: лучшая среда для развития данных ИИ
В отличие от огромной армии удалённых аннотаторов Scale AI (Филиппины, Венесуэла), Web3 обладает уникальными преимуществами на рынке данных ИИ, внедряя концепцию DataFi.
Идеально, если возможности Web3 DataFi включают:
1. Владение данными, безопасность и приватность на смарт-контрактах
Публичные источники данных почти исчерпаны, и доступ к уникальным или приватным данным становится критическим фактором. Отсюда дилемма доверия: продать данные центральному агрегатору или зафиксировать права собственности в блокчейне, чтобы смарт-контракты прозрачно отслеживали, кто, когда и как использует ваши данные?
Для защиты чувствительных данных применяются доказательства с нулевым разглашением и аппаратные TEE-решения, которые гарантируют их доступность только для машин, защищая приватность и предотвращая утечки.
2. Географический арбитраж: децентрализованное участие лучших специалистов со всего мира
Пора иначе взглянуть на глобальные трудовые модели. В отличие от глобального поиска дешёвого труда, как у Scale AI, распределённая архитектура Web3 и прозрачные стимулы смарт-контрактов позволяют талантам по всему миру участвовать в генерации данных и получать справедливое вознаграждение.
Для задач по разметке и валидации моделей децентрализованный подход повышает разнообразие и минимизирует искажения — что особо важно для качества.
3. Прозрачные стимулы и выплаты на блокчейне
Хотите минимизировать операционные риски? Смарт-контракты обеспечивают абсолютную прозрачность и автоматизацию поощрений — это предпочтительнее «чёрных ящиков» ручного управления.
По мере снижения глобализации открытие офисов по всему миру сложнее, а блокчейн-расчёты позволяют обойти эти сложности и упростить трансграничное участие и выплаты.
4. Открытые и эффективные маркетплейсы данных
Комиссии посредников — вечная проблема. Вместо централизованных компаний платформы на блокчейне могут выступать прозрачными маркетплейсами (аналог Taobao), связывая продавцов и покупателей напрямую.
Спрос на данные для ИИ на блокчейне будет становиться все более сложноструктурированным и масштабным, и только децентрализованный рынок способен этого добиться.
DataFi — самый доступный инструмент децентрализованного ИИ для частных пользователей
Хотя инструменты на базе ИИ упростили вход для новичков, а децентрализованный ИИ бросает вызов монополиям, большинство таких проектов всё ещё недоступно массовому непрофессионалу. Для участия в децентрализованных вычислениях требуется дорогостоящее оборудование, маркетплейсы моделей сложны в освоении.
В отличие от этого, Web3 предоставляет уникальный шанс каждому внести вклад в эволюцию ИИ без эксплуатации персональных данных. Достаточно подключить кошелек, чтобы начать вносить данные, размечать результаты моделей, участвовать в оценке или работать с простыми ИИ-инструментами — для опытных аирдроп-участников это не представляет технических трудностей.
Крупнейшие проекты Web3 DataFi: на кого обратить внимание
Движение средств задаёт тренды. Инвестиция Scale AI в Meta на $14,3 млрд и пятикратный рост акций Palantir продемонстрировали потенциал DataFi в Web2; в Web3 сегмент DataFi выделяется по объёмам привлечённого капитала. Вот несколько наиболее заметных проектов:
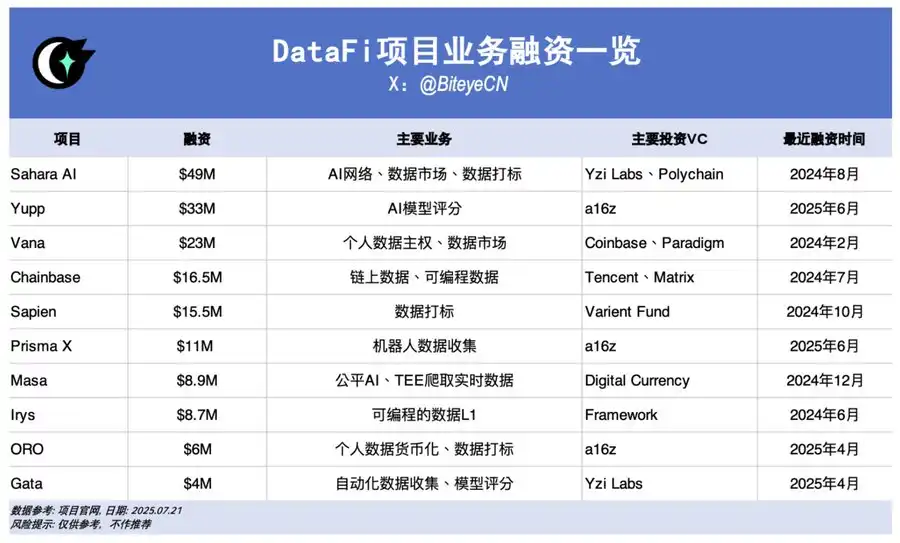
Sahara AI, @SaharaLabsAI, инвестиции — $49 млн
Sahara AI разрабатывает децентрализованную суперинфраструктуру и маркетплейс данных. Бета-версия платформы Data Services Platform (DSP) стартует 22 июля, пользователи получают вознаграждение за вклад и разметку данных.
Сайт: app.saharaai.com
Yupp, @yupp_ai, инвестиции — $33 млн
Yupp — платформа оценки откликов ИИ, где пользователи сравнивают ответы моделей на одинаковые запросы и выбирают лучший. Баллы Yupp можно конвертировать в стейблкоины (например, USDC).
Сайт: https://yupp.ai/
Vana, @vana, инвестиции — $23 млн
Vana позволяет превращать личные данные (история браузера, активность в соцсетях) в цифровые активы. Данные объединяются в DataDAO и пулы ликвидности для обучения ИИ, а авторы получают токены — вознаграждение за вклад.
Сайт: https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, инвестиции — $16,5 млн
Chainbase фокусируется на ончейн-данных: активность более 200 блокчейнов обрабатывается и структурируется в монетизируемые активы для разработчиков DApp с помощью систем Manuscript и Theia AI. Для частных пользователей участие ограничено.
Sapien, @JoinSapien, инвестиции — $15,5 млн
Sapien масштабирует человеческие знания, превращая их в первоклассные обучающие датасеты для ИИ. Любой может вносить разметку, уровень качества контролируется взаимной проверкой, а стейкинг и долгосрочная репутация поощряются увеличением наград.
Сайт: https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, инвестиции — $11 млн
Prisma X разрабатывает открытую координационную платформу для роботов, где сбор реальных данных — основной элемент. Проект на ранней стадии, пользователи могут поддерживать сбор данных, дистанционное управление или участвовать в викторинах для получения баллов.
Сайт: https://app.prismax.ai/whitepaper
Masa, @getmasafi, инвестиции — $8,9 млн
Masa лидирует в экосистеме Bittensor — сабнеты данных и агентов. Сабнет данных предоставляет доступ в реальном времени через TEE-оборудование, собирающее данные X/Twitter. Для частных участников сейчас дорого и сложно.
Irys, @irys_xyz, инвестиции — $8,7 млн
Irys предлагает эффективное и недорогое программируемое хранилище данных и вычисления для ИИ и насыщенных данными DApp. Вариантов для частных пользователей по внесению данных немного, но тестовая сеть открыта для нескольких форм участия.
Сайт: https://bitomokx.irys.xyz/
ORO, @getoro_xyz, инвестиции — $6 млн
ORO даёт возможность каждому участвовать в развитии ИИ, связывая социальные, медицинские или финтех-аккаунты или выполняя задания по сбору данных. Тестовая сеть открыта для всех.
Сайт: app.getoro.xyz
Gata, @Gata_xyz, инвестиции — $4 млн
Децентрализованный слой данных Gata предлагает три ключевых продукта: Data Agent (ИИ-ассистенты в браузере), All-in-one Chat (вознаграждение за работу с моделями — как Yupp), GPT-to-Earn (расширение для сбора диалогов ChatGPT).
Сайт: https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
Как оценивать такие проекты?
Сейчас технический барьер для этих платформ минимален, но устойчивость пользовательской базы и экосистемы нарастает экспоненциально. На ранней стадии важно инвестировать в стимулы и комфорт: кто быстрее привлечёт аудиторию, тот выиграет гонку данных.
Платформы, основанные на человеческом труде, сталкиваются с задачами управления исполнителями и контроля качества. В Web3 часто большая масса участников — краткосрочные «фермеры», что приводит к снижению качества: недобросовестные вытесняют ценных вкладчиков, страдает целостность данных и интерес покупателей. Sahara, Sapien и другие уже придают приоритет значению качества и долгосрочным отношениям с контрибьюторами.
Вторая острая проблема — недостаточная прозрачность. Из-за треугольника компромиссов блокчейна проекты часто стартуют централизованно, а многие по сути воспроизводят логику Web2, несмотря на декларированную децентрализацию: мало ончейн-данных, неясны обязательства по открытости. Это вредит здоровью DataFi. Ждём, что больше команд ускорят движение к прозрачности и открытости.
Для масштабного внедрения DataFi нужны два фактора: привлечение большого числа частных участников для формирования рынка данных и создания замкнутой ИИ-экономики, а также выход на корпоративных клиентов, которые в ближайшее время останутся основным источником выручки. В этих направлениях Sahara AI, Vana и другие уже сделали весомые шаги.
Выводы
DataFi — это стратегия долгосрочного развития машинного интеллекта на основе человеческого участия, где смарт-контракты гарантируют справедливое вознаграждение, а рост потенциала ИИ приносит выгоду каждому.
Если вы испытываете неопределённость в эпоху ИИ или продолжаете верить в блокчейн несмотря на волатильность крипторынка, участие в DataFi — своевременный и разумный шаг.
Отказ от ответственности:
- Статья перепечатана из [BLOCKBEATS], все авторские права — у оригинального автора [anci_hu49074, основной участник Biteye]. По вопросам перепечатки обращайтесь в команду Gate Learn для разрешения спорных ситуаций в соответствии с правилами.
- Данный материал отражает исключительно мнение автора и не является инвестиционной рекомендацией.
- Прочие языковые версии подготовлены командой Gate Learn. Без прямого указания Gate копирование, распространение или плагиат переводов запрещены.
Статьи по теме

Что такое Tronscan и как вы можете использовать его в 2025 году?

Что такое Нейро? Все, что вам нужно знать о NEIROETH в 2025 году

Что такое индикатор кумулятивного объема дельты (CVD)? (2025)

Что такое Solscan и как его использовать? (Обновление 2025 года)

15 криптовалютных проектов уровня 1 (L1), на которые стоит обратить внимание в 2024 году
