TheSmartApe🔥
Пока нет содержимого
TheSmartApe🔥
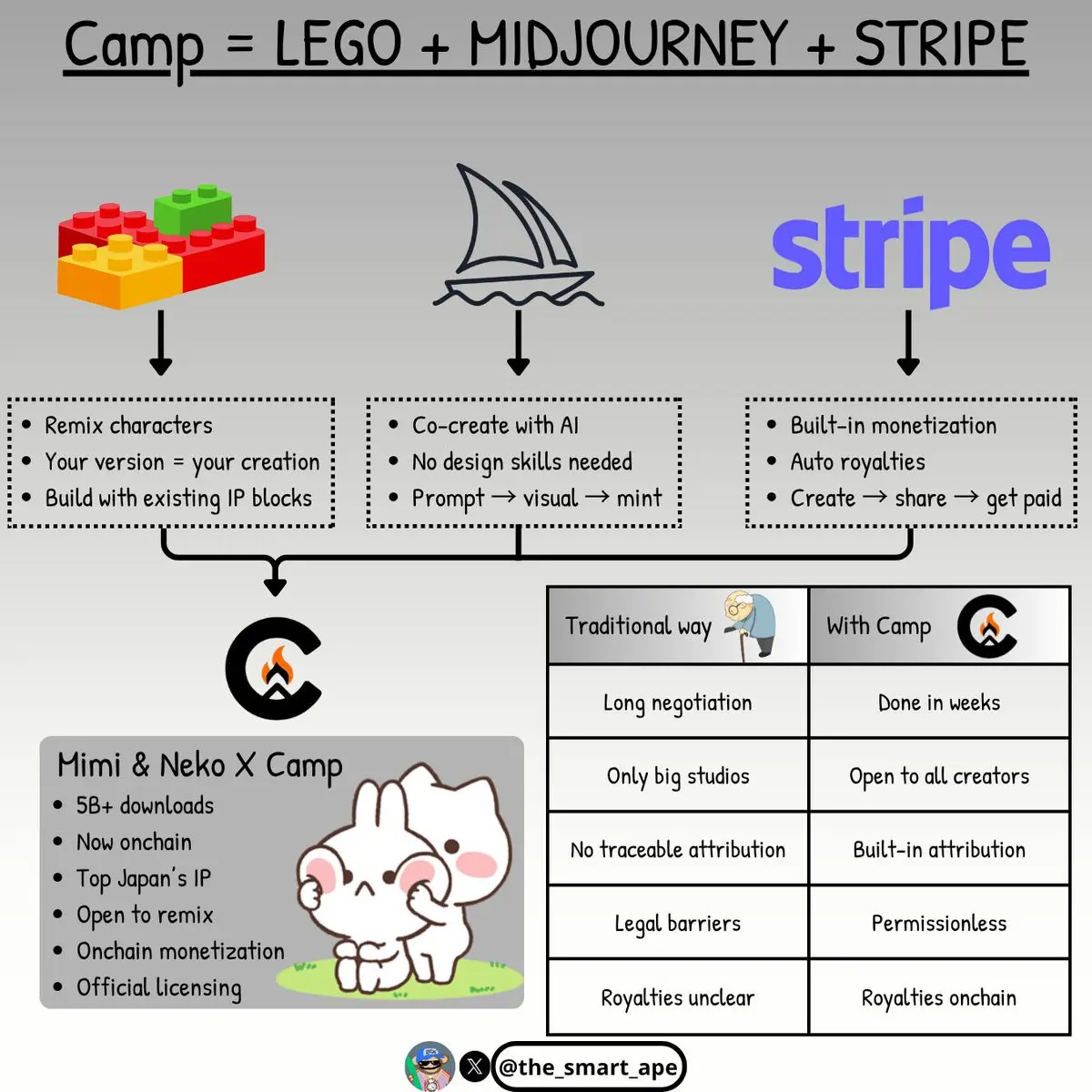
Camp = LEGO + Midjourney + Stripe, всё в одном приложении.
Кампания Mimi & Neko от @campnetworkxyz показывает, что вам больше не нужно быть Disney или Pixar, чтобы работать с крупными интеллектуальными собственностями.
Кэмп говорит: "Вот популярный IP, он открыт, он на блокчейне, строй с ним."
Это похоже на получение набора LEGO и возможность свободно rearranging детали так, как вам хочется.
Вам даже не нужно быть художником, просто используйте свои идеи с подсказками, чтобы создавать новые версии персонажей.
Это похоже на использование Midjourney для ремикса или создания изображения на основе
Посмотреть ОригиналКампания Mimi & Neko от @campnetworkxyz показывает, что вам больше не нужно быть Disney или Pixar, чтобы работать с крупными интеллектуальными собственностями.
Кэмп говорит: "Вот популярный IP, он открыт, он на блокчейне, строй с ним."
Это похоже на получение набора LEGO и возможность свободно rearranging детали так, как вам хочется.
Вам даже не нужно быть художником, просто используйте свои идеи с подсказками, чтобы создавать новые версии персонажей.
Это похоже на использование Midjourney для ремикса или создания изображения на основе
- Награда
- лайк
- комментарий
- Поделиться
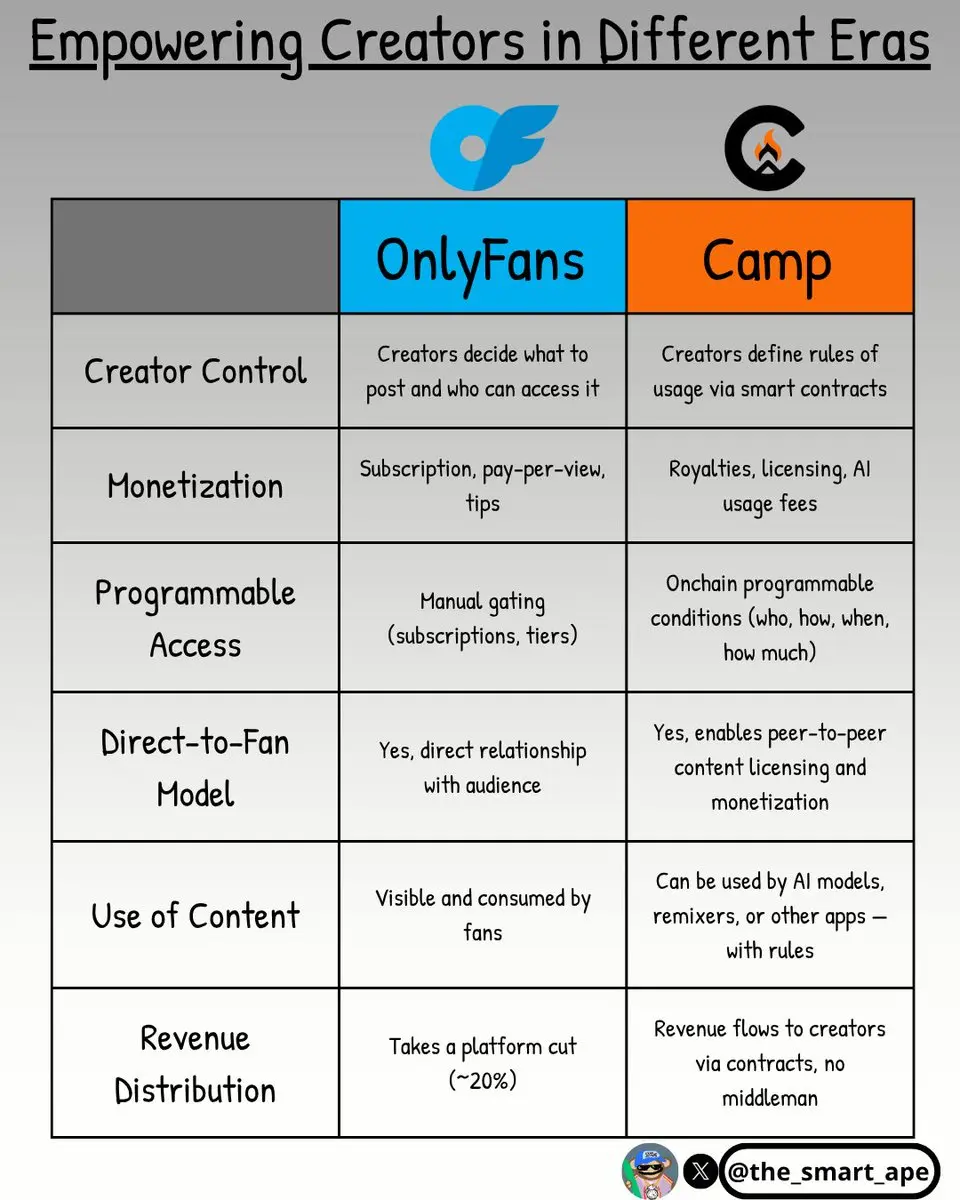
Искусственный интеллект не может функционировать без обучения на данных, которые вы создаете.
Таким образом, оно вынуждено «наблюдать» за вами, чтобы стать лучше.
Camp действует как вратарь, так же как OnlyFans, но для ИИ, он позволяет вам контролировать доступ к вашему контенту с помощью смарт-контрактов.
+ Вы решаете, кто может получить доступ к чему
+ Вы устанавливаете роялти в зависимости от того, как используется ваш контент
+ Больше никаких тихих сборов данных, ваш контент, ваши правила
Таким образом, оно вынуждено «наблюдать» за вами, чтобы стать лучше.
Camp действует как вратарь, так же как OnlyFans, но для ИИ, он позволяет вам контролировать доступ к вашему контенту с помощью смарт-контрактов.
+ Вы решаете, кто может получить доступ к чему
+ Вы устанавливаете роялти в зависимости от того, как используется ваш контент
+ Больше никаких тихих сборов данных, ваш контент, ваши правила
MORE-14.29%
- Награда
- лайк
- комментарий
- Поделиться
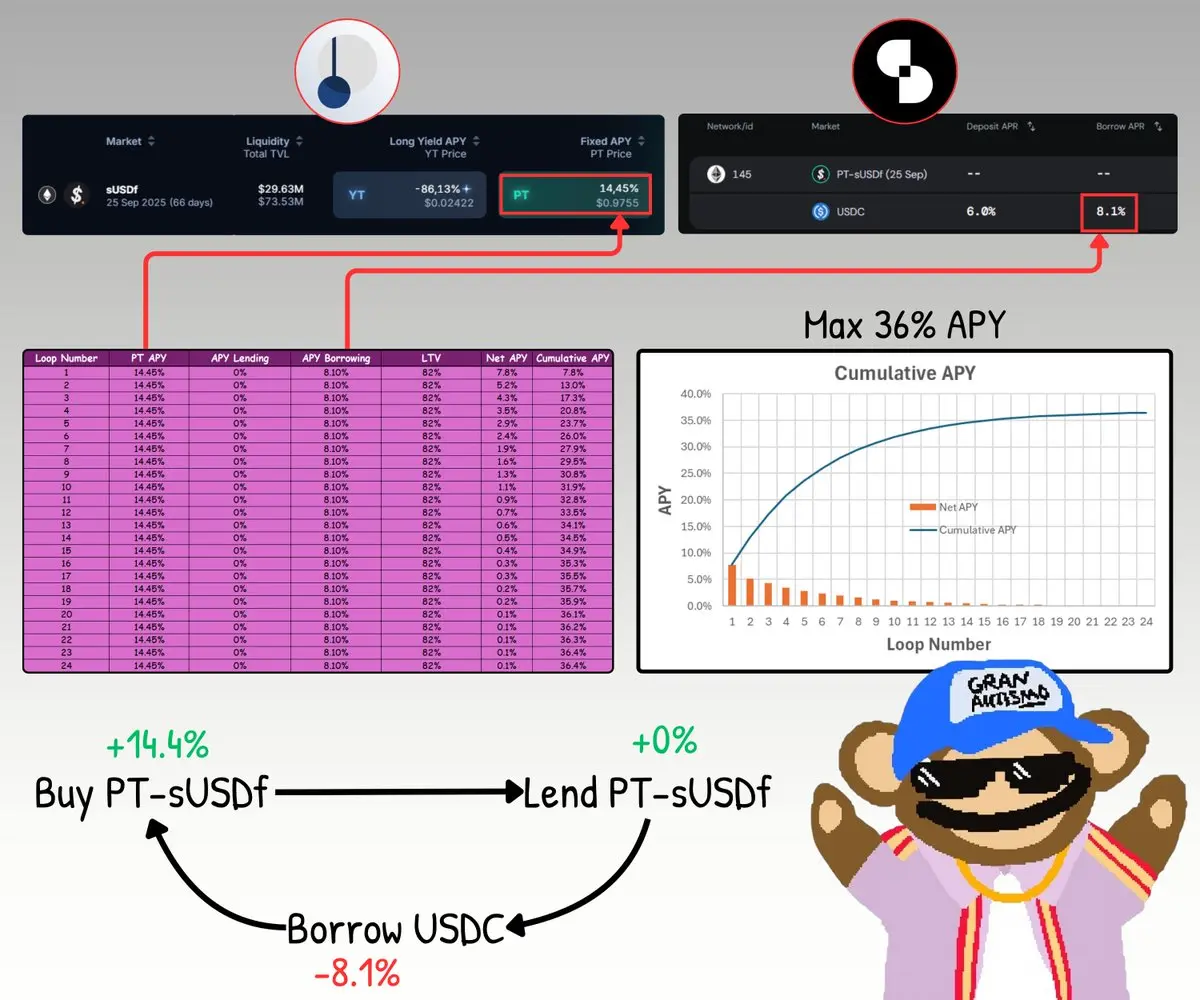
Честно говоря, я не могу придумать более увлекательный способ получать высокие доходы на стейблкоинах.
Вот как это работает:
1/ Купите PT sUSDf на Pendle
Это уже дает вам фиксированную доходность 14,4% APY при погашении.
Но давайте будем честными, 14% само по себе недостаточно. Мы здесь для того, чтобы использовать кредитное плечо.
2/ Займите PT sUSDf на Silo
Вы не получите дополнительный доход от кредитования, но это позволяет вам занимать USDC по стоимости 8%.
3/ Занять USDC под залог PT-sUSDf
4/ Используйте заимствованный USDC, чтобы купить больше токенов sUSDf PT
Затем просто повторите цик
Посмотреть ОригиналВот как это работает:
1/ Купите PT sUSDf на Pendle
Это уже дает вам фиксированную доходность 14,4% APY при погашении.
Но давайте будем честными, 14% само по себе недостаточно. Мы здесь для того, чтобы использовать кредитное плечо.
2/ Займите PT sUSDf на Silo
Вы не получите дополнительный доход от кредитования, но это позволяет вам занимать USDC по стоимости 8%.
3/ Занять USDC под залог PT-sUSDf
4/ Используйте заимствованный USDC, чтобы купить больше токенов sUSDf PT
Затем просто повторите цик
- Награда
- лайк
- 1
- Поделиться
Stocks :
:
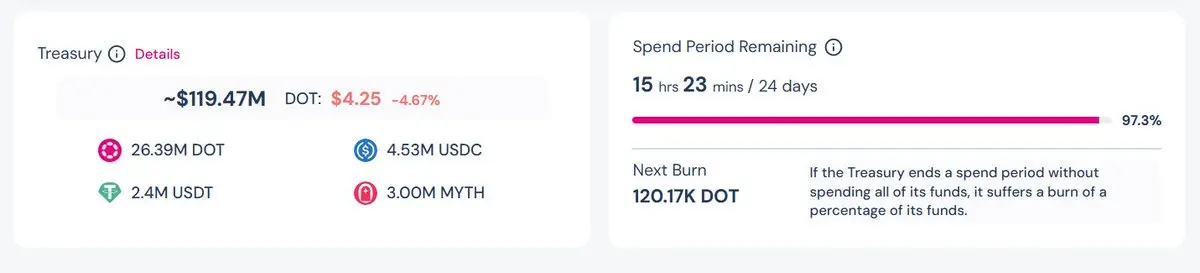
Риски есть, есть ли риск потопления?Назовите одну цепочку, которая передает свое казначейство сообществу и позволяет ему тратить его свободно.
+ Это также побуждает сообщество тратить его. Если они не используют его в течение определенного периода, часть казны сжигается.
+ Это также побуждает сообщество тратить его. Если они не используют его в течение определенного периода, часть казны сжигается.
DON-5.2%
- Награда
- лайк
- комментарий
- Поделиться
Самое большое, что приходит в криптовалюту, это RWA.
Нам не нужен альт-сезон, одного RWA достаточно.
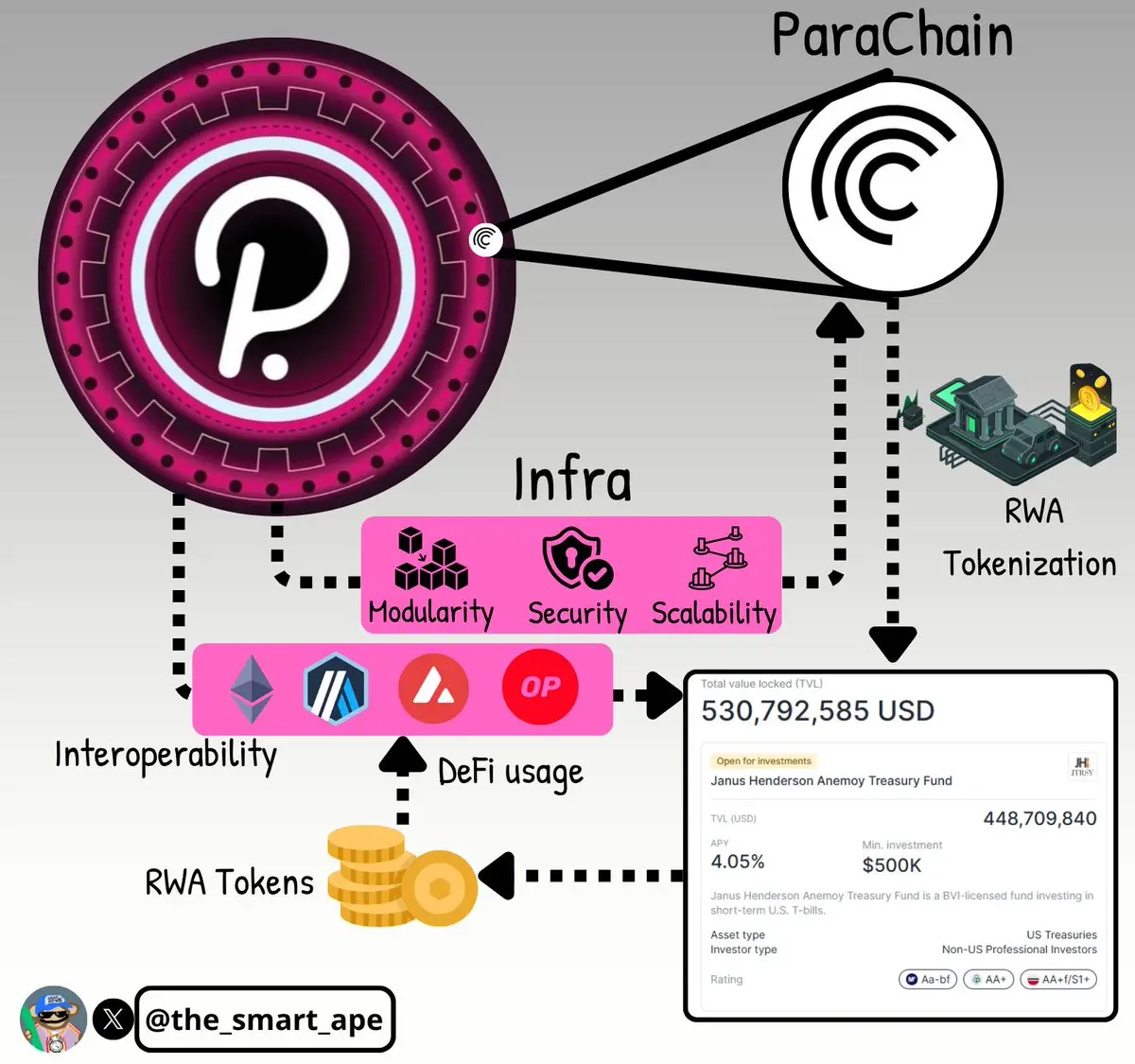
RWA требует инфраструктуры и гибкости, а Polkadot предоставляет и то, и другое.
Как парачейн, Centrifuge извлекает выгоду из общей безопасности набора валидаторов Polkadot, не имея необходимости поддерживать собственную сеть валидаторов.
Благодаря совместимости Polkadot, Centrifuge также может соединяться с другими экосистемами, такими как Ethereum, Arbitrum и Avalanche, легко открывая внешний ликвидность DeFi.
Посмотреть ОригиналНам не нужен альт-сезон, одного RWA достаточно.
RWA требует инфраструктуры и гибкости, а Polkadot предоставляет и то, и другое.
Как парачейн, Centrifuge извлекает выгоду из общей безопасности набора валидаторов Polkadot, не имея необходимости поддерживать собственную сеть валидаторов.
Благодаря совместимости Polkadot, Centrifuge также может соединяться с другими экосистемами, такими как Ethereum, Arbitrum и Avalanche, легко открывая внешний ликвидность DeFi.
- Награда
- лайк
- комментарий
- Поделиться
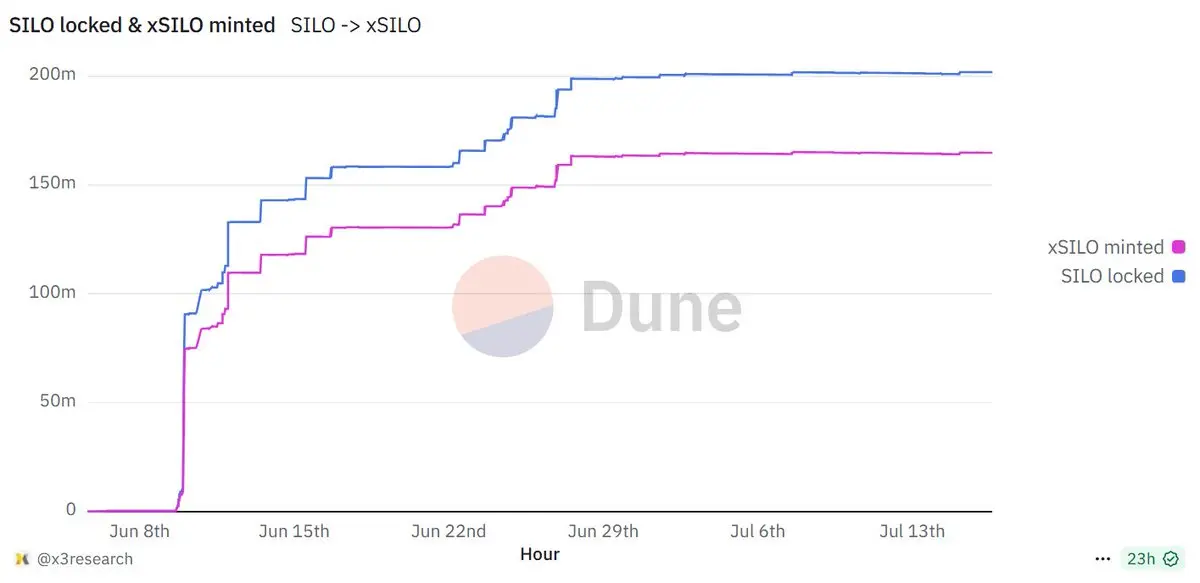
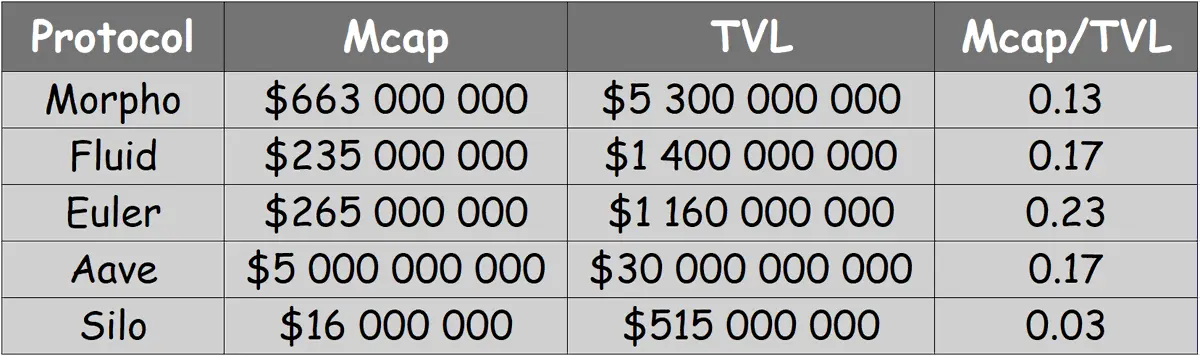
Это только мне кажется, или $SILO полностью неправильно оценен?
Во время гипер DeFi фазы на Sonic они предоставили множество возможностей для получения дохода, и теперь они делают то же самое на Avalanche.
Что действительно удивляет меня, так это рыночная капитализация, всего 16 миллионов долларов, с полной разбавленной капитализацией в 38 миллионов долларов. Это ставит соотношение рыночной капитализации к TVL на уровне 0,03, что является одним из самых низких в этой области на данный момент.
+ 20% от $SILO заблокировано в xSILO, что значительно снижает давление на продажу.
Все показатели указ
Посмотреть ОригиналВо время гипер DeFi фазы на Sonic они предоставили множество возможностей для получения дохода, и теперь они делают то же самое на Avalanche.
Что действительно удивляет меня, так это рыночная капитализация, всего 16 миллионов долларов, с полной разбавленной капитализацией в 38 миллионов долларов. Это ставит соотношение рыночной капитализации к TVL на уровне 0,03, что является одним из самых низких в этой области на данный момент.
+ 20% от $SILO заблокировано в xSILO, что значительно снижает давление на продажу.
Все показатели указ
- Награда
- лайк
- комментарий
- Поделиться
Странно, что происходит Падение на короткий срок, в то время как наблюдается рост на долгий срок.
Посмотреть Оригинал
- Награда
- лайк
- комментарий
- Поделиться
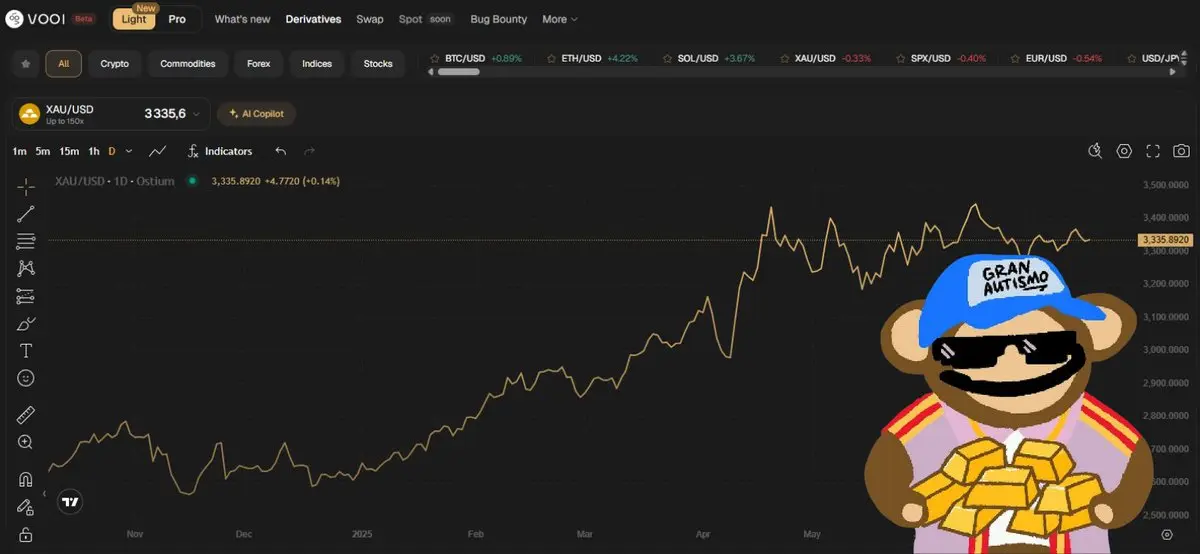
Золото, вероятно, является самым простым активом для торговли в настоящее время, особенно учитывая текущую глобальную политическую и экономическую обстановку.
Когда мир в беспорядке, есть 3 вещи, которые вы должны иметь: золото, земля и, конечно, BTC.
Безграничный, без разрешений, абстрагированный от приложений, честно говоря, мне действительно нравится мой опыт торговли на VOOI.
Посмотреть ОригиналКогда мир в беспорядке, есть 3 вещи, которые вы должны иметь: золото, земля и, конечно, BTC.
Безграничный, без разрешений, абстрагированный от приложений, честно говоря, мне действительно нравится мой опыт торговли на VOOI.
- Награда
- лайк
- комментарий
- Поделиться
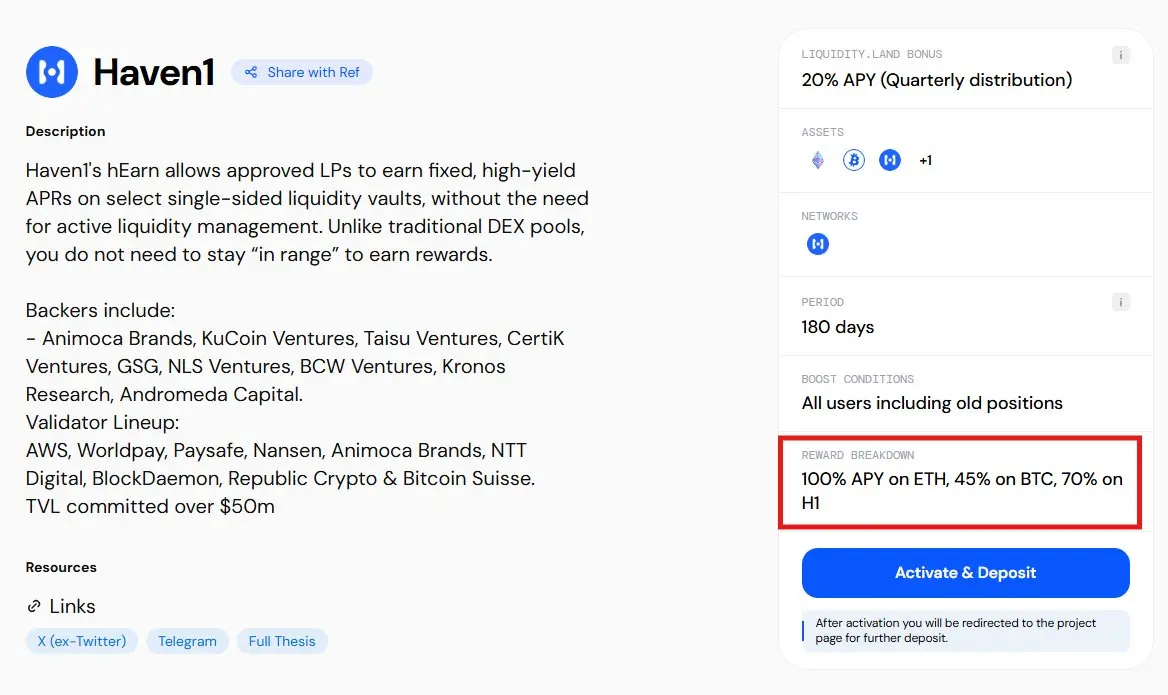
Некоторые хранилища предлагают более 100% APY, и если вы являетесь пользователем L.L, вы получаете 20% увеличение APY, выплачиваемое ежеквартально.
Все контракты проходят двойной аудит, только проверенные разработчики могут развертывать, и такие крупные компании, как WorldPay и Bitcoin Suisse, поддерживают это.
Посмотреть ОригиналВсе контракты проходят двойной аудит, только проверенные разработчики могут развертывать, и такие крупные компании, как WorldPay и Bitcoin Suisse, поддерживают это.
- Награда
- лайк
- комментарий
- Поделиться

- Награда
- лайк
- комментарий
- Поделиться
Не нужно публиковать десятки раз, я сделал только 2 поста на этой неделе.
Самое важное - это предложить свежий взгляд, упростить что-то сложное и предоставить ценность.
Переработка одного и того же поста каждый раз бесполезна ни для вас, ни для вашей аудитории.
Посмотреть ОригиналСамое важное - это предложить свежий взгляд, упростить что-то сложное и предоставить ценность.
Переработка одного и того же поста каждый раз бесполезна ни для вас, ни для вашей аудитории.

- Награда
- лайк
- комментарий
- Поделиться
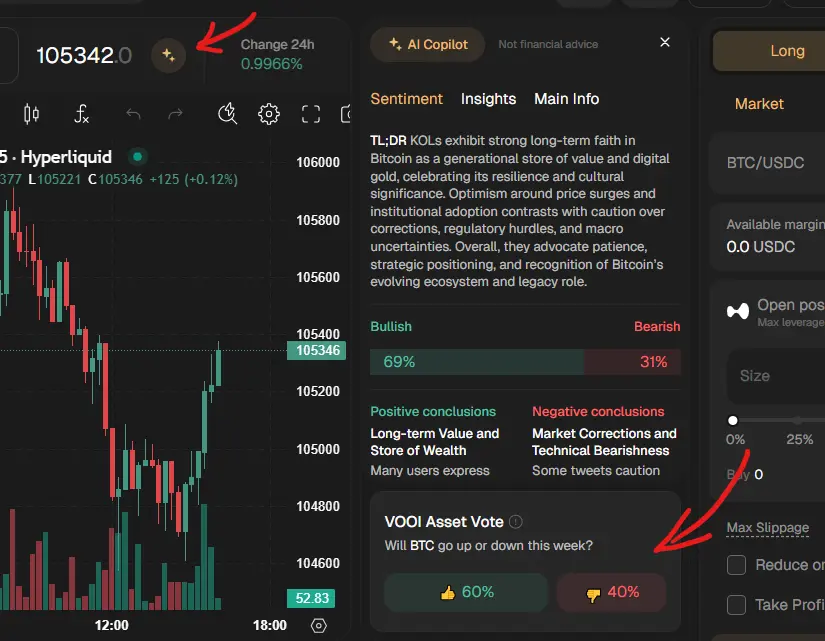
Но то, что действительно сделает разницу, это их предстоящий ИИ-координатор.
Это встроенный помощник, который предоставляет рекомендации в режиме реального времени на основе условий активов. Не могу дождаться, чтобы увидеть, что он сделает для золота и нефти в текущем политическом контексте.
Это встроенный помощник, который предоставляет рекомендации в режиме реального времени на основе условий активов. Не могу дождаться, чтобы увидеть, что он сделает для золота и нефти в текущем политическом контексте.
APP0.31%
- Награда
- лайк
- комментарий
- Поделиться
Существующие LLM, такие как GPT, Claude и другие, достигли своего предела, они уже собрали все данные из открытого интернета и открытых данных.
Остальное — это частный контент с разрешением пользователя, который находится внутри приложений и не может быть просто собран таким образом. Эти данные гораздо более ценны и качественны, но защищены авторским правом и должны быть доступны легитимно.
Вы, вероятно, слышали «ты то, что ты ешь», то же самое относится и к ИИ: что отличает хорошие модели от плохих, так это качество данных, на которых они обучены.
Будущие модели будут полагаться на надежные,
Посмотреть ОригиналОстальное — это частный контент с разрешением пользователя, который находится внутри приложений и не может быть просто собран таким образом. Эти данные гораздо более ценны и качественны, но защищены авторским правом и должны быть доступны легитимно.
Вы, вероятно, слышали «ты то, что ты ешь», то же самое относится и к ИИ: что отличает хорошие модели от плохих, так это качество данных, на которых они обучены.
Будущие модели будут полагаться на надежные,

- Награда
- лайк
- комментарий
- Поделиться
Плохая новость в том, что меня исключили, и я не заработаю ни одного балла в течение следующих 9 дней.
Все в порядке, я могу подождать. Я начну снова через 9 дней, ха-ха.
Цикл: Заходите, зарабатывайте очки, распределяйте их на хорошие проекты, получайте прибыль, ждите и повторяйте.
Посмотреть ОригиналВсе в порядке, я могу подождать. Я начну снова через 9 дней, ха-ха.
Цикл: Заходите, зарабатывайте очки, распределяйте их на хорошие проекты, получайте прибыль, ждите и повторяйте.

- Награда
- лайк
- комментарий
- Поделиться