# 從數據源到智能分析:解析Web3數據索引賽道發展## 1. 引言自2017年首批去中心化應用問世以來,區塊鏈生態系統蓬勃發展,各類dApp如雨後春筍般湧現。在探討這些去中心化應用時,我們是否曾思考過它們所依賴的數據來源?2024年,人工智能與Web3成爲熱點話題。在AI領域,數據猶如生命之源,驅動着智能系統的不斷進化。正如植物需要陽光和水分,AI系統同樣依賴海量數據來學習和思考。沒有數據支持,再先進的AI算法也難以發揮其潛力。本文將深入探討區塊鏈數據可訪問性的演變歷程,比較傳統數據索引協議與新興區塊鏈數據服務的異同,特別關注結合AI技術的新型協議在數據服務和產品架構上的創新。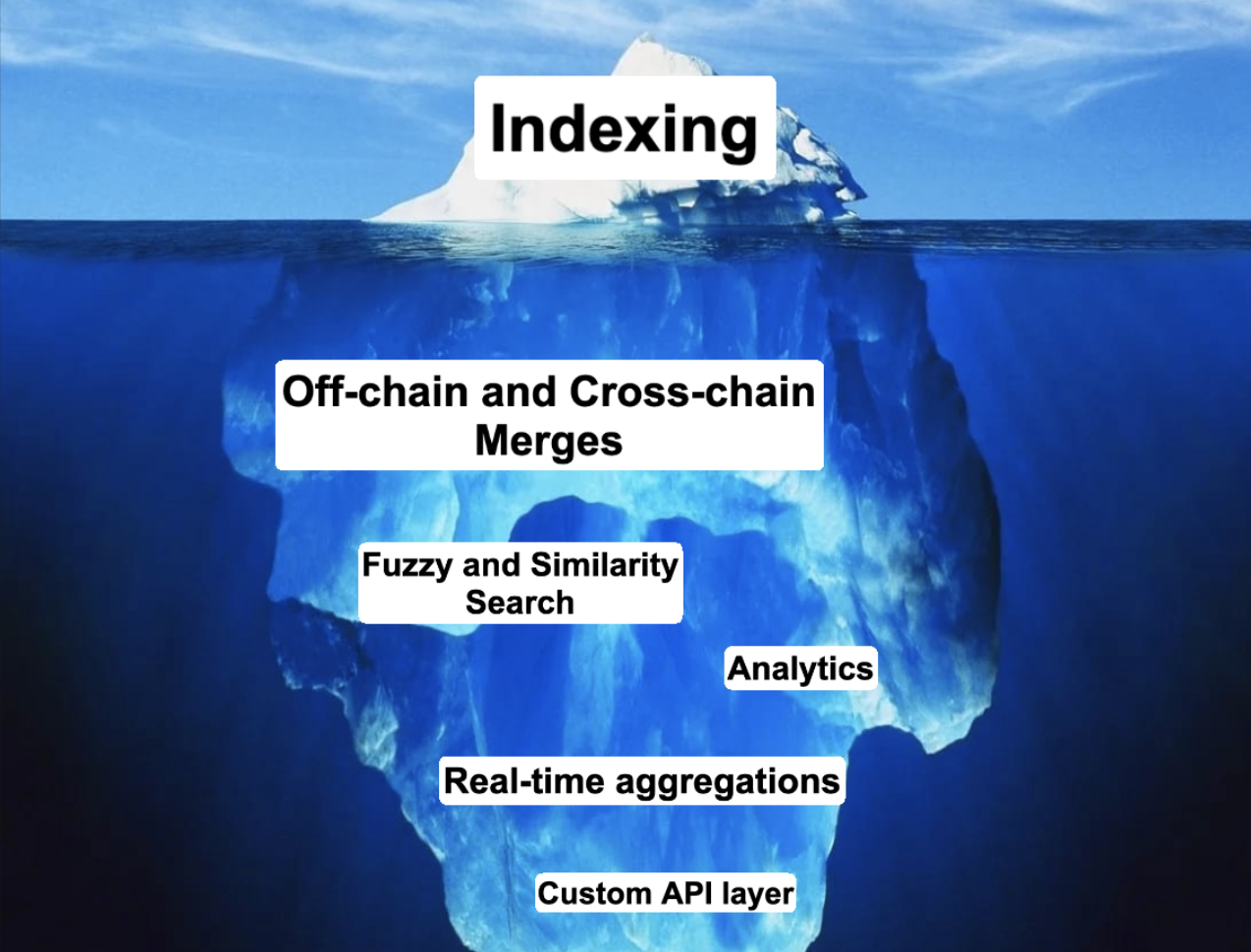## 2. 數據索引的演進:從區塊鏈節點到全鏈數據庫### 2.1 數據源頭:區塊鏈節點區塊鏈被稱爲去中心化的記帳本,而區塊鏈節點則是這一網路的基石,負責記錄、存儲和傳播鏈上交易數據。每個節點都保存完整的區塊鏈數據副本,確保網路的去中心化特性。然而,對普通用戶而言,自建和維護節點不僅技術門檻高,還需承擔昂貴的硬件和帶寬成本。此外,普通節點的查詢能力有限,難以滿足開發者的需求。因此,盡管理論上人人都可運行節點,實際上用戶更傾向於依賴第三方服務。爲解決這一問題,RPC節點提供商應運而生。它們承擔節點管理成本,並通過RPC端點提供數據訪問服務。公共RPC端點免費但有速率限制,可能影響dApp用戶體驗。私有RPC端點性能更佳,但對復雜查詢效率不高,且難以跨網路擴展。盡管如此,節點提供商標準化的API接口降低了用戶訪問鏈上數據的門檻,爲後續數據解析和應用奠定了基礎。### 2.2 數據解析:從原始數據到可用信息區塊鏈節點提供的原始數據通常經過加密和編碼處理,這雖然保證了數據的完整性和安全性,但也增加了解析難度。對普通用戶和開發者而言,直接處理這些數據需要大量技術知識和計算資源。數據解析過程在此背景下顯得尤爲重要。通過將復雜的原始數據轉換爲易理解和操作的格式,用戶可以更直觀地利用這些信息。解析質量直接影響區塊鏈數據應用的效率和效果,是整個數據索引流程中的關鍵環節。### 2.3 數據索引器的發展隨着區塊鏈數據量激增,數據索引器的需求日益突出。索引器負責組織鏈上數據並將其導入數據庫以便查詢。它們通過索引區塊鏈數據,並提供類SQL查詢語言(如GraphQL)的API接口,使數據隨時可用。索引器爲開發者提供了統一的查詢界面,大大簡化了數據檢索流程。不同類型的索引器各有優勢:1. 完整節點索引器:直接從完整節點提取數據,確保數據完整性,但需大量存儲和處理能力。2. 輕量級索引器:依賴完整節點獲取特定數據,減少存儲需求但可能增加查詢時間。3. 專用索引器:針對特定數據類型或區塊鏈優化,如NFT數據或DeFi交易。4. 聚合索引器:從多個區塊鏈和來源提取數據,包括鏈下信息,提供統一查詢界面,適合多鏈dApp。目前,以太坊檔案節點在不同客戶端下佔用空間從3TB到13.5TB不等。面對如此龐大的數據量,主流索引器協議不僅支持多鏈索引,還針對不同應用需求定制了數據解析框架,如The Graph的"子圖"框架。索引器的出現大幅提升了數據索引和查詢效率。與傳統RPC端點相比,索引器能高效處理大量數據,支持復雜查詢和數據過濾。某些索引器還支持聚合多個區塊鏈的數據,避免多鏈dApp需要部署多個API的問題。通過分布式運行,索引器提供了更強的安全性和性能,降低了集中式RPC提供商可能帶來的中斷風險。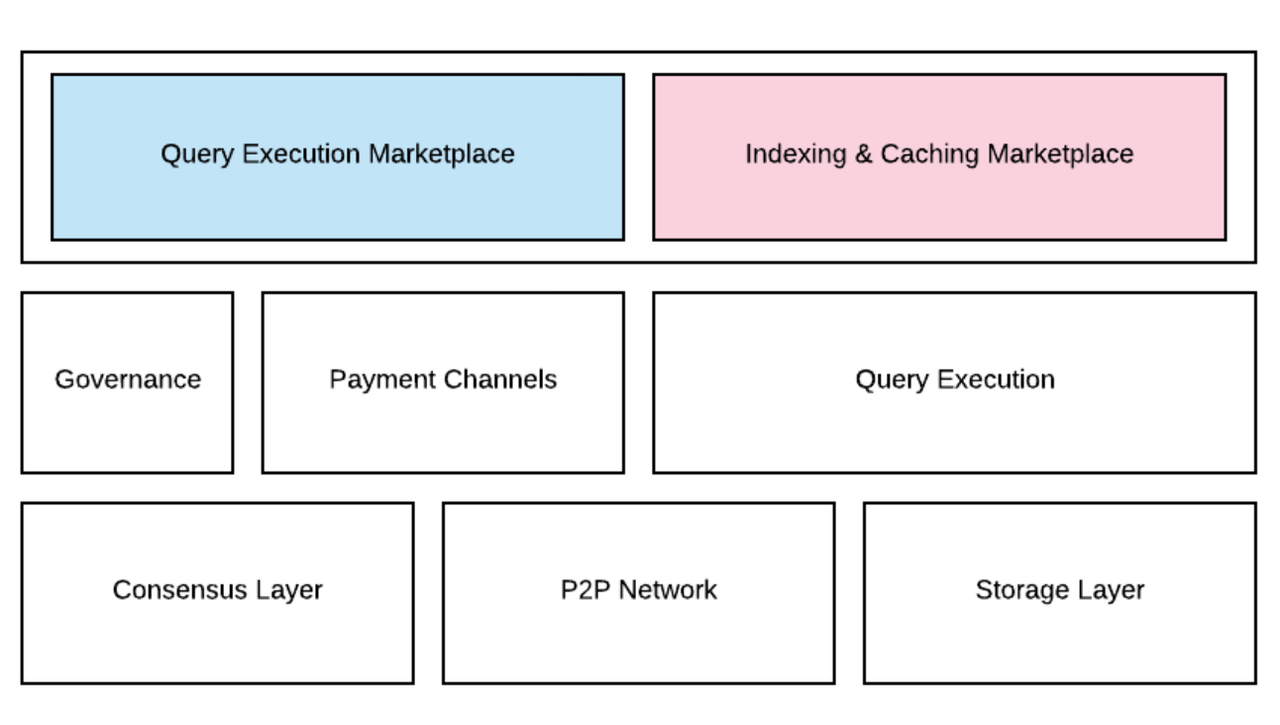### 2.4 全鏈數據庫:向流優先對齊隨着應用需求復雜化,初級數據索引器及其標準化格式難以滿足多樣化的查詢需求,如搜索、跨鏈訪問或鏈下數據映射。區塊鏈數據服務提供商正朝着構建數據流的方向發展,以滿足實時解析和全面查詢的需求。傳統索引器服務商紛紛推出數據流產品,如The Graph的Substreams和Goldsky的Mirror。同時,新興服務如Chainbase和SubSquid也提供基於區塊鏈生成的實時數據湖。這些服務旨在通過更先進的數據源支持應用程序發展並輔助鏈上數據分析。通過現代數據管道的視角重新審視鏈上數據,我們可以設想一個能爲任何業務用例定制高性能數據集的未來。## 3. AI與數據庫的融合:The Graph、Chainbase和Space and Time的比較分析### 3.1 The GraphThe Graph網路通過去中心化節點提供多鏈數據索引和查詢服務,便於開發者構建去中心化應用。其核心產品模式包括數據查詢執行市場和數據索引緩存市場,服務於用戶的查詢需求。網路由索引器、策展人、委托人和開發者四個角色構成,通過經濟激勵確保系統運轉。索引器提供索引和查詢服務,委托者支持索引節點運營,策展人篩選有價值的子圖,開發者則是主要用戶。The Graph生態系統正積極擁抱AI技術。Semiotic Labs開發的AutoAgora、Allocation Optimizer和AgentC等工具,分別優化了索引定價、資源分配和用戶查詢體驗,提升了系統的智能化和用戶友好度。### 3.2 ChainbaseChainbase作爲全鏈數據網路,整合各區塊鏈數據,簡化開發者構建和維護應用的過程。其特色功能包括:- 實時數據湖:提供即時訪問的區塊鏈數據流。- 雙鏈架構:基於Eigenlayer AVS構建執行層,與CometBFT共識算法並行,增強跨鏈數據處理能力。- 創新數據格式:引入"manuscripts"標準,優化加密行業數據結構。- 加密世界模型:結合AI技術,打造能理解、預測區塊鏈交易的模型,如基礎版Theia。Chainbase的AI模型Theia基於NVIDIA的DORA模型,結合鏈上外數據分析加密模式,通過因果推理做出響應,深入挖掘鏈上數據價值,提供智能化數據服務。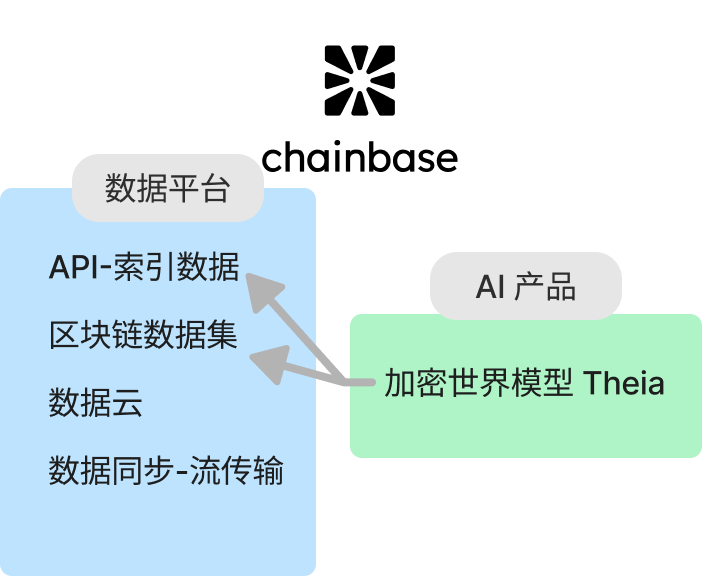### 3.3 Space and TimeSpace and Time (SxT)致力於構建可驗證的計算層,在去中心化數據倉庫上擴展零知識證明,爲智能合約、大語言模型和企業提供可信數據處理。SxT引入了創新的Proof of SQL技術,這是一種零知識證明技術,確保在去中心化數據倉庫上執行的SQL查詢結果可驗證且防篡改。與傳統區塊鏈網路依賴共識機制不同,SxT通過一個節點獲取數據,其他節點使用zk技術驗證數據真實性,提高了系統性能。SxT與微軟AI實驗室合作,開發生成式AI工具,簡化用戶通過自然語言處理區塊鏈數據的過程。在Space and Time Studio中,用戶可輸入自然語言查詢,AI自動轉換爲SQL並執行,呈現最終結果。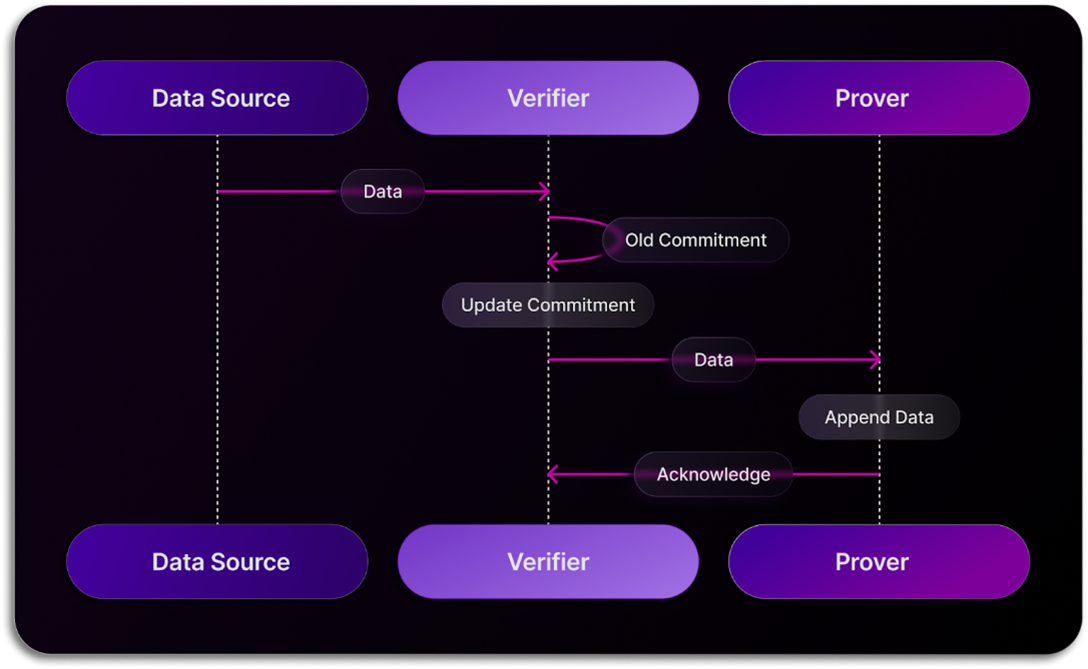## 結論與展望區塊鏈數據索引技術從最初的節點數據源,經過數據解析和索引器的發展,最終演進到AI賦能的全鏈數據服務,經歷了逐步完善的過程。這些技術的進步不僅提高了數據訪問效率和準確性,還爲用戶帶來了智能化體驗。未來,隨着AI技術和零知識證明等新技術的發展,區塊鏈數據服務將進一步智能化和安全化。作爲基礎設施,區塊鏈數據服務將繼續在行業創新中發揮重要作用。


Web3數據索引發展新趨勢:AI賦能全鏈數據服務
從數據源到智能分析:解析Web3數據索引賽道發展
1. 引言
自2017年首批去中心化應用問世以來,區塊鏈生態系統蓬勃發展,各類dApp如雨後春筍般湧現。在探討這些去中心化應用時,我們是否曾思考過它們所依賴的數據來源?
2024年,人工智能與Web3成爲熱點話題。在AI領域,數據猶如生命之源,驅動着智能系統的不斷進化。正如植物需要陽光和水分,AI系統同樣依賴海量數據來學習和思考。沒有數據支持,再先進的AI算法也難以發揮其潛力。
本文將深入探討區塊鏈數據可訪問性的演變歷程,比較傳統數據索引協議與新興區塊鏈數據服務的異同,特別關注結合AI技術的新型協議在數據服務和產品架構上的創新。
2. 數據索引的演進:從區塊鏈節點到全鏈數據庫
2.1 數據源頭:區塊鏈節點
區塊鏈被稱爲去中心化的記帳本,而區塊鏈節點則是這一網路的基石,負責記錄、存儲和傳播鏈上交易數據。每個節點都保存完整的區塊鏈數據副本,確保網路的去中心化特性。然而,對普通用戶而言,自建和維護節點不僅技術門檻高,還需承擔昂貴的硬件和帶寬成本。此外,普通節點的查詢能力有限,難以滿足開發者的需求。因此,盡管理論上人人都可運行節點,實際上用戶更傾向於依賴第三方服務。
爲解決這一問題,RPC節點提供商應運而生。它們承擔節點管理成本,並通過RPC端點提供數據訪問服務。公共RPC端點免費但有速率限制,可能影響dApp用戶體驗。私有RPC端點性能更佳,但對復雜查詢效率不高,且難以跨網路擴展。盡管如此,節點提供商標準化的API接口降低了用戶訪問鏈上數據的門檻,爲後續數據解析和應用奠定了基礎。
2.2 數據解析:從原始數據到可用信息
區塊鏈節點提供的原始數據通常經過加密和編碼處理,這雖然保證了數據的完整性和安全性,但也增加了解析難度。對普通用戶和開發者而言,直接處理這些數據需要大量技術知識和計算資源。
數據解析過程在此背景下顯得尤爲重要。通過將復雜的原始數據轉換爲易理解和操作的格式,用戶可以更直觀地利用這些信息。解析質量直接影響區塊鏈數據應用的效率和效果,是整個數據索引流程中的關鍵環節。
2.3 數據索引器的發展
隨着區塊鏈數據量激增,數據索引器的需求日益突出。索引器負責組織鏈上數據並將其導入數據庫以便查詢。它們通過索引區塊鏈數據,並提供類SQL查詢語言(如GraphQL)的API接口,使數據隨時可用。索引器爲開發者提供了統一的查詢界面,大大簡化了數據檢索流程。
不同類型的索引器各有優勢:
目前,以太坊檔案節點在不同客戶端下佔用空間從3TB到13.5TB不等。面對如此龐大的數據量,主流索引器協議不僅支持多鏈索引,還針對不同應用需求定制了數據解析框架,如The Graph的"子圖"框架。
索引器的出現大幅提升了數據索引和查詢效率。與傳統RPC端點相比,索引器能高效處理大量數據,支持復雜查詢和數據過濾。某些索引器還支持聚合多個區塊鏈的數據,避免多鏈dApp需要部署多個API的問題。通過分布式運行,索引器提供了更強的安全性和性能,降低了集中式RPC提供商可能帶來的中斷風險。
2.4 全鏈數據庫:向流優先對齊
隨着應用需求復雜化,初級數據索引器及其標準化格式難以滿足多樣化的查詢需求,如搜索、跨鏈訪問或鏈下數據映射。區塊鏈數據服務提供商正朝着構建數據流的方向發展,以滿足實時解析和全面查詢的需求。
傳統索引器服務商紛紛推出數據流產品,如The Graph的Substreams和Goldsky的Mirror。同時,新興服務如Chainbase和SubSquid也提供基於區塊鏈生成的實時數據湖。這些服務旨在通過更先進的數據源支持應用程序發展並輔助鏈上數據分析。
通過現代數據管道的視角重新審視鏈上數據,我們可以設想一個能爲任何業務用例定制高性能數據集的未來。
3. AI與數據庫的融合:The Graph、Chainbase和Space and Time的比較分析
3.1 The Graph
The Graph網路通過去中心化節點提供多鏈數據索引和查詢服務,便於開發者構建去中心化應用。其核心產品模式包括數據查詢執行市場和數據索引緩存市場,服務於用戶的查詢需求。
網路由索引器、策展人、委托人和開發者四個角色構成,通過經濟激勵確保系統運轉。索引器提供索引和查詢服務,委托者支持索引節點運營,策展人篩選有價值的子圖,開發者則是主要用戶。
The Graph生態系統正積極擁抱AI技術。Semiotic Labs開發的AutoAgora、Allocation Optimizer和AgentC等工具,分別優化了索引定價、資源分配和用戶查詢體驗,提升了系統的智能化和用戶友好度。
3.2 Chainbase
Chainbase作爲全鏈數據網路,整合各區塊鏈數據,簡化開發者構建和維護應用的過程。其特色功能包括:
Chainbase的AI模型Theia基於NVIDIA的DORA模型,結合鏈上外數據分析加密模式,通過因果推理做出響應,深入挖掘鏈上數據價值,提供智能化數據服務。
3.3 Space and Time
Space and Time (SxT)致力於構建可驗證的計算層,在去中心化數據倉庫上擴展零知識證明,爲智能合約、大語言模型和企業提供可信數據處理。
SxT引入了創新的Proof of SQL技術,這是一種零知識證明技術,確保在去中心化數據倉庫上執行的SQL查詢結果可驗證且防篡改。與傳統區塊鏈網路依賴共識機制不同,SxT通過一個節點獲取數據,其他節點使用zk技術驗證數據真實性,提高了系統性能。
SxT與微軟AI實驗室合作,開發生成式AI工具,簡化用戶通過自然語言處理區塊鏈數據的過程。在Space and Time Studio中,用戶可輸入自然語言查詢,AI自動轉換爲SQL並執行,呈現最終結果。
結論與展望
區塊鏈數據索引技術從最初的節點數據源,經過數據解析和索引器的發展,最終演進到AI賦能的全鏈數據服務,經歷了逐步完善的過程。這些技術的進步不僅提高了數據訪問效率和準確性,還爲用戶帶來了智能化體驗。
未來,隨着AI技術和零知識證明等新技術的發展,區塊鏈數據服務將進一步智能化和安全化。作爲基礎設施,區塊鏈數據服務將繼續在行業創新中發揮重要作用。
从统计学的角度来看,这些ai-web3混合体中有94.3%只是进化的死胡同。