PhyrexNi
PhyrexNi
用戶暫無簡介
- 讚賞
- 1
- 留言
- 分享
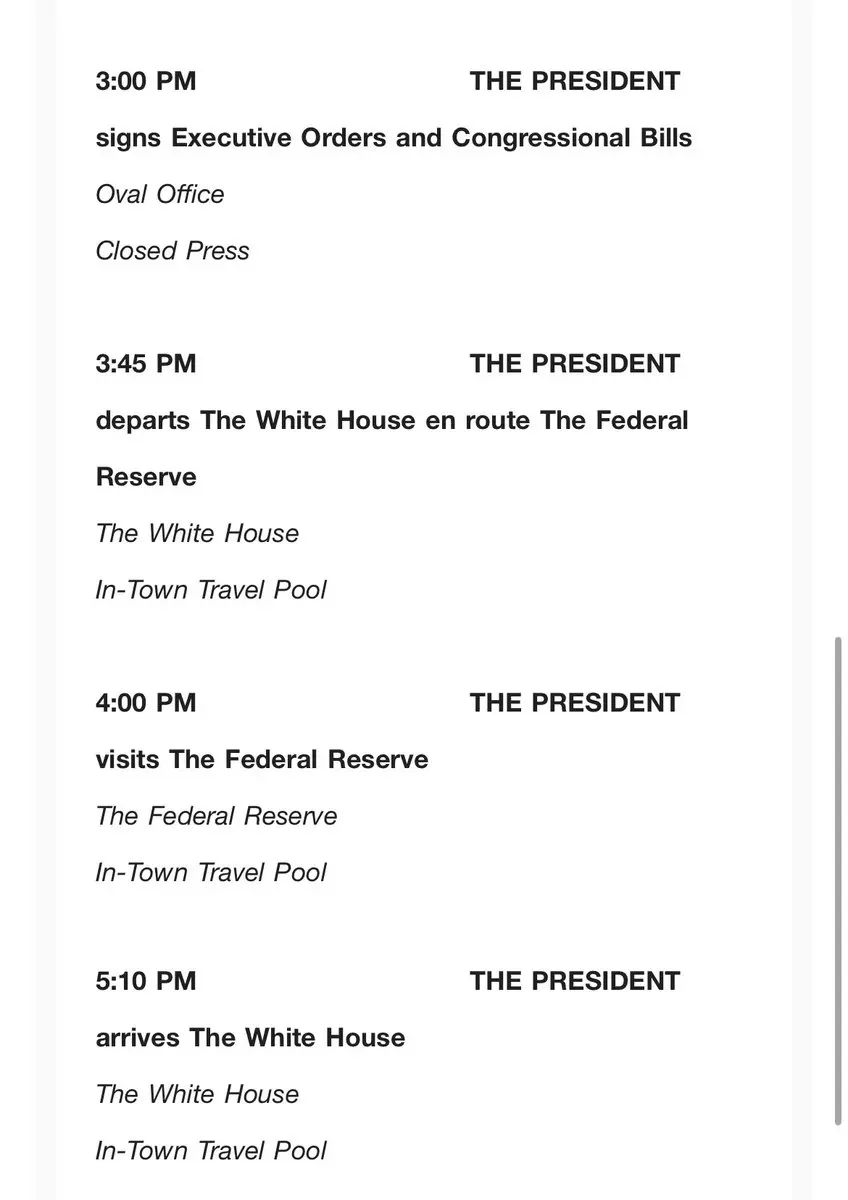
當川普爲 AI 投入萬億時,誰在爲 AI 提供可信數據?
當川普爲 AI 投入萬億美元時,表面看上去是模型、芯片、數據中心的比拼,但也引發出更深層的問題,AI 模型依賴的數據是如何驗證的,是否可追蹤的,在訓練過程黑箱和推理過程是不是可以審計的,模型之間是否可以協作,還是只能各自爲戰?
說人話就是當我們共 AI 獲取信息的時候,誰能確定 AI 給出的信息就是對的,數據污染已經不是一個說着玩的詞了,當初某號稱是 ChatGPT 殺手的 AI 應用就已經深深的陷入了到數據污染的環境,當數據源都是錯誤的時候,給出的答案如何能是正確的。
現在的AI是不是智能的?也許是,但即便是再聰明的 AI 也需要模型的訓練,但我們無法知道模型訓練用了哪些數據,也無法驗證 GPU 是否真的跑完了一個推理過程,更無法在多個模型間建立互信邏輯。
如果要讓 AI 真正走向下一代,可能需要同時解決這三個問題:
一,訓練數據必須可信、可驗證。
二,推理過程必須可被第三方模型審計。
三,模型必須能在無需平台撮合的前提下協調算力、交換任務、共享成果。
這不是單靠一個模型、一個 API 或一個 GPU 平台能解決的,而是需要一個真正爲 AI 構建的系統,這個系統應該既能低成本永久性的存儲數據,讓數據本身具備審查與被審查的權限,又能讓模型之間實現推理上的驗證,還需要要支持模型在特定前提下自主發現算力、協調任務、審計每一步執行
查看原文當川普爲 AI 投入萬億美元時,表面看上去是模型、芯片、數據中心的比拼,但也引發出更深層的問題,AI 模型依賴的數據是如何驗證的,是否可追蹤的,在訓練過程黑箱和推理過程是不是可以審計的,模型之間是否可以協作,還是只能各自爲戰?
說人話就是當我們共 AI 獲取信息的時候,誰能確定 AI 給出的信息就是對的,數據污染已經不是一個說着玩的詞了,當初某號稱是 ChatGPT 殺手的 AI 應用就已經深深的陷入了到數據污染的環境,當數據源都是錯誤的時候,給出的答案如何能是正確的。
現在的AI是不是智能的?也許是,但即便是再聰明的 AI 也需要模型的訓練,但我們無法知道模型訓練用了哪些數據,也無法驗證 GPU 是否真的跑完了一個推理過程,更無法在多個模型間建立互信邏輯。
如果要讓 AI 真正走向下一代,可能需要同時解決這三個問題:
一,訓練數據必須可信、可驗證。
二,推理過程必須可被第三方模型審計。
三,模型必須能在無需平台撮合的前提下協調算力、交換任務、共享成果。
這不是單靠一個模型、一個 API 或一個 GPU 平台能解決的,而是需要一個真正爲 AI 構建的系統,這個系統應該既能低成本永久性的存儲數據,讓數據本身具備審查與被審查的權限,又能讓模型之間實現推理上的驗證,還需要要支持模型在特定前提下自主發現算力、協調任務、審計每一步執行
- 讚賞
- 4
- 1
- 分享
Flowergirl34 :
:
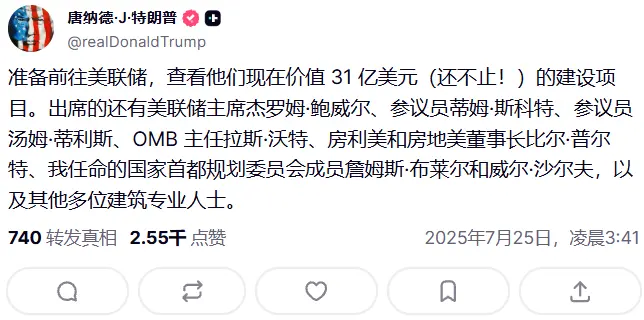
牛市 🐂韓國總統府:產業部長向美國商務部長提出互利方案,美國表示了興趣。尚未聽說關於延長8月1日談判截止日期的消息。韓國外匯問題超出正常磋商範圍,已納入談判內容。
查看原文- 讚賞
- 1
- 留言
- 分享
金融時報報道:歐盟馮德萊恩告訴,歐中關係處於轉折點,歐盟要求解決與中國的貿易順差問題,與中國重新平衡關係非可選項。
查看原文- 讚賞
- 6
- 1
- 分享
jaabri008:
#Gate ETH 10th Anniversary Celebration# #Trump’s AI Strategy# #Gate Launchpad List IKA# HODL 緊密 💪