AI互验机制真给力,信任就该这么建立!
Meta11
用户暂无简介
Meta11
最近刷到一个项目叫 Fresco,第一眼看上去还以为是类似于Midjourney 的同类产品,但深入玩了一下之后,发现它其实不只是个“生成图工具”,更像是一次“你和幻想世界的对话”。
Fresco 是为 Mira 世界服务的,充满奇幻氛围的设定宇宙,里面的主角是一群骑士。但这些骑士不是系统随机分配的,而是用户通过写prompt亲手“召唤”出来的。
每天只有一次机会写一句话,这句话会变成你当天的召唤仪式。你写的是什么场景,它就会给你一个做这件事的骑士。不是画一个人物,而是一个角色。这种感觉就像是你萌发出一个念头,然后 Mira 用活生生的角色来回应你。
更厉害的是,这个骑士的风格、气质、动作,都会带着 Mira 的美学体系。有点偏中世纪复古的感觉。看上去都像是有自己使命的个体。
Fresco 的次数限制,反而成了它最吸引人的点。你只有一天一次机会,不能撤回,不能重来。意味着每一个 prompt 背后生成的不光是图,还有角色的命运。
我觉得 Fresco 特别像一种“仪式化创作”。它不是那种无限刷图的快餐工具,而是把幻想当成一种信念来对待。写一句话,换一个回应。每天最期待的就是新的变化.
同时 @Mira_Network 还推出 Fresco Gallery,能看到别人的 prompt 和他们召唤出来的角色。这个部分特别像逛社区,大家把自己写下的幻想都展示出来,每一个都不一样,一千
Fresco 是为 Mira 世界服务的,充满奇幻氛围的设定宇宙,里面的主角是一群骑士。但这些骑士不是系统随机分配的,而是用户通过写prompt亲手“召唤”出来的。
每天只有一次机会写一句话,这句话会变成你当天的召唤仪式。你写的是什么场景,它就会给你一个做这件事的骑士。不是画一个人物,而是一个角色。这种感觉就像是你萌发出一个念头,然后 Mira 用活生生的角色来回应你。
更厉害的是,这个骑士的风格、气质、动作,都会带着 Mira 的美学体系。有点偏中世纪复古的感觉。看上去都像是有自己使命的个体。
Fresco 的次数限制,反而成了它最吸引人的点。你只有一天一次机会,不能撤回,不能重来。意味着每一个 prompt 背后生成的不光是图,还有角色的命运。
我觉得 Fresco 特别像一种“仪式化创作”。它不是那种无限刷图的快餐工具,而是把幻想当成一种信念来对待。写一句话,换一个回应。每天最期待的就是新的变化.
同时 @Mira_Network 还推出 Fresco Gallery,能看到别人的 prompt 和他们召唤出来的角色。这个部分特别像逛社区,大家把自己写下的幻想都展示出来,每一个都不一样,一千
PROMPT-1.12%


- 赞赏
- 点赞
- 评论
- 分享
最近刷到的一个关键词叫:AI版权战。主角不是谁侵权谁的问题,而是整个 AI 产业到底是不是在挖别人的矿,盖自己的楼。
从 Reddit 告 Anthropic,到 Getty 告 Stability AI,再到 Disney 起诉 Midjourney,一连串大厂对 AI 公司的集体反击,表面看是个别事件,其实背后是同一个核心问题,AI 模型在没有经过授权的情况下,从网络上抓了太多创作者的内容来训练模型。
这事的本质不是技术问题,而是利益分配问题。AI 公司借用了内容创作者的劳动成果,却没有给到任何回报。这不是零和博弈的游戏,而是明抢。现实情况是AI 产业挖的矿来自创作者的劳动,但收益和控制权却集中掌握在极少数的科技公司手中。
@campnetworkxyz 不是去对抗 AI,而是让 AI 和创作者一起共赢。构建一个基于链上版权 + 智能合约 + 可验证许可系统的新秩序,让创作者的贡献被看见、被认可、被回报。
Camp 的底层思路是,用上链的方式来解决AI所带来的系统性问题。也就是说,创作者的作品上链,IP 权属链上登记,许可合约写进智能合约,AI 在用任何一份内容前都必须有明确授权,不仅能查、还能自动结算使用费。说白了就是创作记录可查、使用行为可追、回报机制可编程。
举个例子,一幅插画被注册上链,每当 AI 模型从数据集中使用这幅图像训练一次,智能合约就自动从资金池里转一笔 mi
从 Reddit 告 Anthropic,到 Getty 告 Stability AI,再到 Disney 起诉 Midjourney,一连串大厂对 AI 公司的集体反击,表面看是个别事件,其实背后是同一个核心问题,AI 模型在没有经过授权的情况下,从网络上抓了太多创作者的内容来训练模型。
这事的本质不是技术问题,而是利益分配问题。AI 公司借用了内容创作者的劳动成果,却没有给到任何回报。这不是零和博弈的游戏,而是明抢。现实情况是AI 产业挖的矿来自创作者的劳动,但收益和控制权却集中掌握在极少数的科技公司手中。
@campnetworkxyz 不是去对抗 AI,而是让 AI 和创作者一起共赢。构建一个基于链上版权 + 智能合约 + 可验证许可系统的新秩序,让创作者的贡献被看见、被认可、被回报。
Camp 的底层思路是,用上链的方式来解决AI所带来的系统性问题。也就是说,创作者的作品上链,IP 权属链上登记,许可合约写进智能合约,AI 在用任何一份内容前都必须有明确授权,不仅能查、还能自动结算使用费。说白了就是创作记录可查、使用行为可追、回报机制可编程。
举个例子,一幅插画被注册上链,每当 AI 模型从数据集中使用这幅图像训练一次,智能合约就自动从资金池里转一笔 mi
IP-0.92%

- 赞赏
- 点赞
- 评论
- 分享
从 @Mira_Network 的工作机制拆解如何辨别AI说的是真话!
现在的大多数用LLM模型的AI,经常一本正经的胡说八道,其实都没法做到可信。不是技术不行,是原理上就存在限制,无法同时要它准确又中立。
你训练的数据越多,越能减少偏见,但容易开始编故事。数据清洗得越干净,可能就更偏向某种立场。
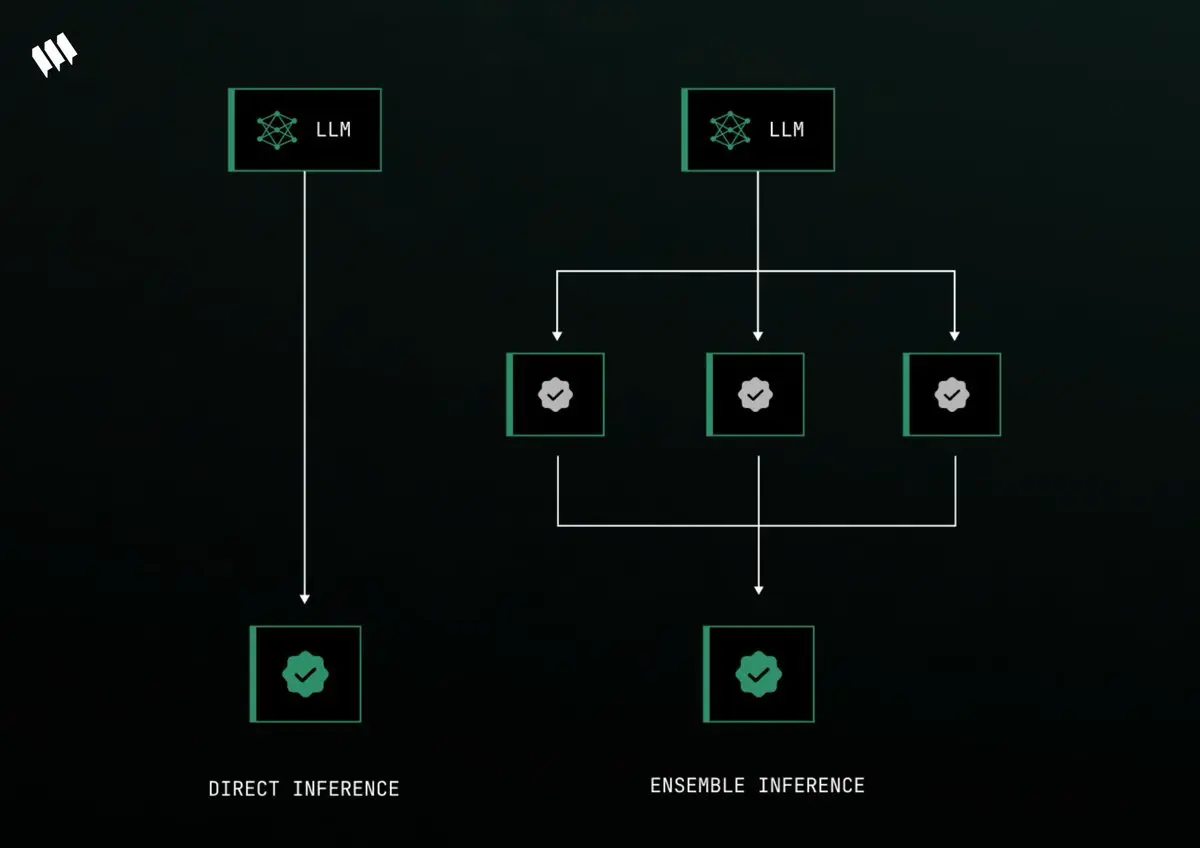
Mira 的核心机制是共识验证。其实就是不再依赖一个模型的回答,通过多个模型一起参与判断。只有当大家都说是,这条回答才算通过验证。
整个流程分为以下三步!
1⃣Binarization
AI 的回答不是一整段拿去判断,而是拆分成一句一句的小判断。
比如:地球绕着太阳转,月亮绕着地球转。
Mira 会把这句话拆成:
地球绕着太阳转
月亮绕着地球转
每一句话都会被独立验证。它避免了整体听起来好像对,其实细节全错的问题。
2⃣分布式验证
这些拆出来的语句会被送到 Mira 网络中的不同验证节点,每个节点都是一个模型或一组模型,它们不会看到完整的上下文,只负责判断自己那一条真假,保证验证更中立。
3⃣验证共识机制
Mira 的“工作量证明”是真实的 AI 推理。
每个验证模型都要 stake(质押)代币,验证完回答要给出结果。
如果表现不好会被“slash”,扣掉质押的代币。
模型的“共识计算”必须几乎所有模型都同意一条判断才算通过。这种机制,就是在用模型间的“多元共识”来逼近事实本身。
说到底
现在的大多数用LLM模型的AI,经常一本正经的胡说八道,其实都没法做到可信。不是技术不行,是原理上就存在限制,无法同时要它准确又中立。
你训练的数据越多,越能减少偏见,但容易开始编故事。数据清洗得越干净,可能就更偏向某种立场。
Mira 的核心机制是共识验证。其实就是不再依赖一个模型的回答,通过多个模型一起参与判断。只有当大家都说是,这条回答才算通过验证。
整个流程分为以下三步!
1⃣Binarization
AI 的回答不是一整段拿去判断,而是拆分成一句一句的小判断。
比如:地球绕着太阳转,月亮绕着地球转。
Mira 会把这句话拆成:
地球绕着太阳转
月亮绕着地球转
每一句话都会被独立验证。它避免了整体听起来好像对,其实细节全错的问题。
2⃣分布式验证
这些拆出来的语句会被送到 Mira 网络中的不同验证节点,每个节点都是一个模型或一组模型,它们不会看到完整的上下文,只负责判断自己那一条真假,保证验证更中立。
3⃣验证共识机制
Mira 的“工作量证明”是真实的 AI 推理。
每个验证模型都要 stake(质押)代币,验证完回答要给出结果。
如果表现不好会被“slash”,扣掉质押的代币。
模型的“共识计算”必须几乎所有模型都同意一条判断才算通过。这种机制,就是在用模型间的“多元共识”来逼近事实本身。
说到底
- 赞赏
- 点赞
- 评论
- 分享
刚看到 @TheoriqAI 发的帖子,讲到 TheoRooAI 和 Yapybara “逃离暗森林”然后踏上自动驾驶之旅,就像 AlphaSwarm 承诺的一步步赢得 DeFi 信任一样。
他们通过漫画的形式想表达AI agent 在DeFi 世界里,就像开车探索一样,需要积累里程才能建立信任。
AlphaSwarm 是 Theoriq 推出的 Agent Swarm 工具包,核心是用一套完整的 Python SDK,快速构建 LLM 驱动的 AI 金融代理,实现跨链交易、流动性补给、收益优化等策略自动执行。
它把三个角色代理组合成一个闭环系统,Portal Agent 负责观察用户状态,Knowledge Agent 拉数据给策略分析,LP Assistant 负责生成可执行代码建议,最终一键发交易。过程透明安全,用户资产始终自托管 。
这种分工模式其实就是团队协作。每个 agent 专职做一部分,一起配合完成复杂任务。
它背后的信任模型通过链上registration、reputation scores、任务结果记录,如果agent 不靠谱,就会被降权甚至失信。每个 agent 都要拿出“业绩”才能被信任。没有靠预期和吹牛逼上位的agent。和Tesla 的自动驾驶如出一辙,你开车开得好,才给你信任,系统必须在用户真实表现后才能被用。
技术上AlphaSwarm 不用 LL
他们通过漫画的形式想表达AI agent 在DeFi 世界里,就像开车探索一样,需要积累里程才能建立信任。
AlphaSwarm 是 Theoriq 推出的 Agent Swarm 工具包,核心是用一套完整的 Python SDK,快速构建 LLM 驱动的 AI 金融代理,实现跨链交易、流动性补给、收益优化等策略自动执行。
它把三个角色代理组合成一个闭环系统,Portal Agent 负责观察用户状态,Knowledge Agent 拉数据给策略分析,LP Assistant 负责生成可执行代码建议,最终一键发交易。过程透明安全,用户资产始终自托管 。
这种分工模式其实就是团队协作。每个 agent 专职做一部分,一起配合完成复杂任务。
它背后的信任模型通过链上registration、reputation scores、任务结果记录,如果agent 不靠谱,就会被降权甚至失信。每个 agent 都要拿出“业绩”才能被信任。没有靠预期和吹牛逼上位的agent。和Tesla 的自动驾驶如出一辙,你开车开得好,才给你信任,系统必须在用户真实表现后才能被用。
技术上AlphaSwarm 不用 LL

- 赞赏
- 点赞
- 评论
- 分享
是谁偷偷偷走你的💰?大家都知道AI的底层逻辑是离不开喂养,而喂养AI的燃料自然是“数据”。还记得之前肝NFT的时候,有一段时间不知道是谁想出来的给社区做二创图片,让得一堆“落榜美术生”焕发出职业生涯的第二春,为此还有很多人找身边学美术的搞工作室。根据质量高低,价格从50-500不等。放到现在,直接把社区相关的素材图扔进去,找AI生成出一堆二创,绝对意义上的费时而不费力。
刚也是刷到 @campnetworkxyz 公布的数据,关于 DataComp CommonPool 的抽样审计。仅仅抽样审计了 0.1%的作品,就已经发现里面包含了成千上万未经授权的创作者作品。而这些数据,正是如今商业 AI 模型的核心训练料。换句话说,大模型赚走了本应属于你的钱,而你分儿币没有。
甚至说创作者连挣扎的机会都没有,因为大部分模型的训练时间是2014-2022年,那个时候别说对什么协议许可和版税机制有什么认知了,甚至对AI都还没什么认知。可能对比币圈的用户来说,版税认知的第一课是来自于Opensea,在交易小图片最后算利润的时候才知道创作者和平台赚的是什么🤣
现在的问题是这些模型已经开始商业化了,从卖API接口、卖生成图、卖订阅。甚至像Stable Diffusion、Midjourney 已经赚的盆满钵满。而创作者却被悄悄的偷走一切。
Camp @campnetworkxyz 现在在做的事情
刚也是刷到 @campnetworkxyz 公布的数据,关于 DataComp CommonPool 的抽样审计。仅仅抽样审计了 0.1%的作品,就已经发现里面包含了成千上万未经授权的创作者作品。而这些数据,正是如今商业 AI 模型的核心训练料。换句话说,大模型赚走了本应属于你的钱,而你分儿币没有。
甚至说创作者连挣扎的机会都没有,因为大部分模型的训练时间是2014-2022年,那个时候别说对什么协议许可和版税机制有什么认知了,甚至对AI都还没什么认知。可能对比币圈的用户来说,版税认知的第一课是来自于Opensea,在交易小图片最后算利润的时候才知道创作者和平台赚的是什么🤣
现在的问题是这些模型已经开始商业化了,从卖API接口、卖生成图、卖订阅。甚至像Stable Diffusion、Midjourney 已经赚的盆满钵满。而创作者却被悄悄的偷走一切。
Camp @campnetworkxyz 现在在做的事情
IP-0.92%

- 赞赏
- 点赞
- 评论
- 分享
现在在 Camp 上共创内容的人,其实早就不只是“早期用户”这么简单了,都是整个新IP经济体系里的真正“权益方”。
这句话听上去有点抽象,但是现在在 @campnetworkxyz 上创作的每一条叙事、每一张图、每一个分支衍生的IP,都有可能成为 AI 模型训练、商业授权、甚至影视改编中的“数据资产节点”,而创作者就是那个节点的原始贡献者、合法权利人。
毕竟Camp想构建的是以“链上确权+AI训练数据”为底层的新型IP经济模型。
传统的内容创作,作品如果要想变现,需要走完全部的中心化的流程,从平台控制到商业化难度,再到最终收益分配——对创作者是极其不友好的。但 Camp 的逻辑是从“链上确权”开始,不管创作的是一张图片、一个角色设定、一段故事剧情,哪怕是某个分支剧情的“二创”,只要你在 Camp 上链,它就自带 provenance(溯源)和可追踪的创作记录。
像这次 Camp 跟Sahara的合作就很有代表性。他们把 Origin、mAItrix 等 Camp 上的 IP 系列,直接接入了 Sahara 的去中心化 AI 数据服务平台。这背后实际就是把 IP 衍生内容,变成 AI 模型训练的数据资产。这些资产不仅具有内容价值,还能在 AI 应用落地后获得“数据层”的激励收益。
这一步让创作不再只是社交属性或精神表达,而是变成了有实打实经济权利的“链上劳动”。从“创作-确权-训练
这句话听上去有点抽象,但是现在在 @campnetworkxyz 上创作的每一条叙事、每一张图、每一个分支衍生的IP,都有可能成为 AI 模型训练、商业授权、甚至影视改编中的“数据资产节点”,而创作者就是那个节点的原始贡献者、合法权利人。
毕竟Camp想构建的是以“链上确权+AI训练数据”为底层的新型IP经济模型。
传统的内容创作,作品如果要想变现,需要走完全部的中心化的流程,从平台控制到商业化难度,再到最终收益分配——对创作者是极其不友好的。但 Camp 的逻辑是从“链上确权”开始,不管创作的是一张图片、一个角色设定、一段故事剧情,哪怕是某个分支剧情的“二创”,只要你在 Camp 上链,它就自带 provenance(溯源)和可追踪的创作记录。
像这次 Camp 跟Sahara的合作就很有代表性。他们把 Origin、mAItrix 等 Camp 上的 IP 系列,直接接入了 Sahara 的去中心化 AI 数据服务平台。这背后实际就是把 IP 衍生内容,变成 AI 模型训练的数据资产。这些资产不仅具有内容价值,还能在 AI 应用落地后获得“数据层”的激励收益。
这一步让创作不再只是社交属性或精神表达,而是变成了有实打实经济权利的“链上劳动”。从“创作-确权-训练


- 赞赏
- 点赞
- 评论
- 分享
- 赞赏
- 点赞
- 评论
- 分享
短短不到一周,已经有 15 万页内容在 Camp 上被 mint 出来了,而且每一页都是链上可验证、版权清晰、可追溯的。不是那种 AI 写完谁都不知道是谁的内容,而是真正意义上的“有源头的共创”。
这事儿让我想到一个问题——过去我们说内容创作的价值很大,但到底属于谁?很多平台会拿走你大部分的控制权和收益权,你写的东西反而成了平台训练算法的“燃料”。
而 Camp + StoryChain 这一套体系,其实就是一种全新的“内容协作协定”:
1️⃣你写的内容可以明确标记为你的 IP
2️⃣AI 的参与过程是透明的,可验证的
3️⃣每一页创作都 mint 成链上资产
4️⃣用户能参与收益分配,有版权归属
在我看来这不仅仅是一个写故事的活动,更像是一个“内容发行新模型”的Beta版本:从用户出发,AI 辅助创作,再通过区块链保证归属与价值回流。说到底,核心逻辑就是用户共创,AI放大,链上确权。
未来我们看到的小说、漫画、剧本,也许真的会从这类机制中诞生。
这事儿让我想到一个问题——过去我们说内容创作的价值很大,但到底属于谁?很多平台会拿走你大部分的控制权和收益权,你写的东西反而成了平台训练算法的“燃料”。
而 Camp + StoryChain 这一套体系,其实就是一种全新的“内容协作协定”:
1️⃣你写的内容可以明确标记为你的 IP
2️⃣AI 的参与过程是透明的,可验证的
3️⃣每一页创作都 mint 成链上资产
4️⃣用户能参与收益分配,有版权归属
在我看来这不仅仅是一个写故事的活动,更像是一个“内容发行新模型”的Beta版本:从用户出发,AI 辅助创作,再通过区块链保证归属与价值回流。说到底,核心逻辑就是用户共创,AI放大,链上确权。
未来我们看到的小说、漫画、剧本,也许真的会从这类机制中诞生。

- 赞赏
- 点赞
- 评论
- 分享
现在 D’CENT 作为钱包也接入了 Camp,其实意味着这条链的底层生态开始往真实使用场景靠拢了。
如果你是创作者,哪怕只是随手拍了个视频、画了幅画、写了段文字,这些内容放在现在只能上传平台换点流量,但现在可以通过 D’CENT 上链注册,明确告诉所有 AI 模型和用户:这个内容是我原创的,我保留使用权、授权权和收益权。
这背后的核心逻辑就是 Camp 推的「Proof of Provenance」——可验证的来源证明。因为是链上记录,有迹可循。平台不能乱改,AI 模型要用得付费,收益按协议费用打给你。这比传统的“内容平台分成模式”更加干净。
设计思路从内容本身是资产这个逻辑出发,围绕创作者建立完整的链上经济闭环。从生成,到确权,到授权,到收益,全流程搞定,甚至还能把这些数据开放给 AI 模型训练,变成透明可追踪的训练数据,而不是黑盒。
未来 AI 模型的应用越多、训练数据越重要。内容的所有权就越值钱。谁能提供明确、真实、可验证的内容资产,谁就能掌握主动权。而不是像现在一样,平台一改条款,AI 就能合法吸走你所有上传的数据。
如果你是创作者,哪怕只是随手拍了个视频、画了幅画、写了段文字,这些内容放在现在只能上传平台换点流量,但现在可以通过 D’CENT 上链注册,明确告诉所有 AI 模型和用户:这个内容是我原创的,我保留使用权、授权权和收益权。
这背后的核心逻辑就是 Camp 推的「Proof of Provenance」——可验证的来源证明。因为是链上记录,有迹可循。平台不能乱改,AI 模型要用得付费,收益按协议费用打给你。这比传统的“内容平台分成模式”更加干净。
设计思路从内容本身是资产这个逻辑出发,围绕创作者建立完整的链上经济闭环。从生成,到确权,到授权,到收益,全流程搞定,甚至还能把这些数据开放给 AI 模型训练,变成透明可追踪的训练数据,而不是黑盒。
未来 AI 模型的应用越多、训练数据越重要。内容的所有权就越值钱。谁能提供明确、真实、可验证的内容资产,谁就能掌握主动权。而不是像现在一样,平台一改条款,AI 就能合法吸走你所有上传的数据。
- 赞赏
- 点赞
- 评论
- 分享
举个最常见的例子,你拿 GPT 去做财务数据分析、工业设备监控、医疗文书归类,大部分输出的结果要么答非所问,要么全靠 prompt 拼命调,调到最后你都不知道它到底懂不懂你要的是什么。
当然很多人想说,难道AI模型不就是不断训练的一个过程。只要你给他喂足够多的数据,他一定会想你所想,给你所要。其实不然,对于个人而言最理想的方式当然是做一个你自己专属的 AI 模型,懂你的数据、适配你的业务。
但实际面临的问题接踵而至,做到这些的前提是你需要有海量的数据、训练模型的人、最重要的是要有跑模型的基础设施,基本上可以劝退 90% 的人。
1️⃣提示调用接口
可以直接通过 /v1/completions 接口调任何部署好的 SLM(Specialized Language Model)。
适配范围很广:AI bot、链上推理、甚至游戏脚本都能用。
2️⃣模型管理接口
通过 /v1/models,可以调出所有现成的模型,既有你自己训练的,也有别人共享出来的。
如果想看详细的信息?使用 /model/info 就能查价格、推理模式、访问权限组这些配置参数。甚至还支持 team_id 管理,兼容 OpenAI 工具,能按访问权限分组,非常适合团队协作和权限控制。
3️⃣费用与支出追踪
链上调用模型都不是免费的,但关键在于这笔钱去了哪?
OpenLedger 给到了完全透明的追踪机制:
每次调用产生的
当然很多人想说,难道AI模型不就是不断训练的一个过程。只要你给他喂足够多的数据,他一定会想你所想,给你所要。其实不然,对于个人而言最理想的方式当然是做一个你自己专属的 AI 模型,懂你的数据、适配你的业务。
但实际面临的问题接踵而至,做到这些的前提是你需要有海量的数据、训练模型的人、最重要的是要有跑模型的基础设施,基本上可以劝退 90% 的人。
1️⃣提示调用接口
可以直接通过 /v1/completions 接口调任何部署好的 SLM(Specialized Language Model)。
适配范围很广:AI bot、链上推理、甚至游戏脚本都能用。
2️⃣模型管理接口
通过 /v1/models,可以调出所有现成的模型,既有你自己训练的,也有别人共享出来的。
如果想看详细的信息?使用 /model/info 就能查价格、推理模式、访问权限组这些配置参数。甚至还支持 team_id 管理,兼容 OpenAI 工具,能按访问权限分组,非常适合团队协作和权限控制。
3️⃣费用与支出追踪
链上调用模型都不是免费的,但关键在于这笔钱去了哪?
OpenLedger 给到了完全透明的追踪机制:
每次调用产生的
- 赞赏
- 8
- 4
- 分享
Waqar56:
好查看更多
如果今天让你重新设计整个 Web3 应用架构——你会从哪开始?
所谓 intent-centric 架构,说白了就是把“用户想要什么”变成第一优先级的需求,不再是按钮后的隐藏参数,而是整个系统运转的中心。
用户只需要描述“我想干嘛”,剩下的匹配、条件约束、对手方查找、最后的交付,全由系统自动协调。
比如我说:“我想用 100 个 stETH 换等值的 RWA 资产,必须是最优性价比,并且今天之内完成。”
如果自己来做这个动作,要么找 aggregators 做路由,要么在多个池子里下单、比较、等成交,还不一定能达成。而在 intent-centric 系统中,这个需求会被解构成明确的意图,广播出去,让有能力 fulfill 的 solver 来处理并 settle。
Anoma 把这种系统拆解成四大模块:
1⃣Intent:用户的愿望、约束条件
2⃣Counterparty Discovery:找到可以匹配的另一方
3⃣Solving:找到最优方案
4⃣Settlement:最终交付和链上达成
这四块其实就构成了未来应用的最小公因式。
很多你熟悉的复杂 DApp,比如 OpenSea、Gitcoin、CoWSwap,归根到底也都围绕这几个动作在运作。只是传统架构让这套流程又重又碎,用户体验不统一,开发难度还高。
intent-centric 的好处,就是把这一切抽象出来、标准化。最
所谓 intent-centric 架构,说白了就是把“用户想要什么”变成第一优先级的需求,不再是按钮后的隐藏参数,而是整个系统运转的中心。
用户只需要描述“我想干嘛”,剩下的匹配、条件约束、对手方查找、最后的交付,全由系统自动协调。
比如我说:“我想用 100 个 stETH 换等值的 RWA 资产,必须是最优性价比,并且今天之内完成。”
如果自己来做这个动作,要么找 aggregators 做路由,要么在多个池子里下单、比较、等成交,还不一定能达成。而在 intent-centric 系统中,这个需求会被解构成明确的意图,广播出去,让有能力 fulfill 的 solver 来处理并 settle。
Anoma 把这种系统拆解成四大模块:
1⃣Intent:用户的愿望、约束条件
2⃣Counterparty Discovery:找到可以匹配的另一方
3⃣Solving:找到最优方案
4⃣Settlement:最终交付和链上达成
这四块其实就构成了未来应用的最小公因式。
很多你熟悉的复杂 DApp,比如 OpenSea、Gitcoin、CoWSwap,归根到底也都围绕这几个动作在运作。只是传统架构让这套流程又重又碎,用户体验不统一,开发难度还高。
intent-centric 的好处,就是把这一切抽象出来、标准化。最

- 赞赏
- 1
- 评论
- 分享
在使用AI的过程中,我们去问它一个问题,它回答得头头是道,可我们没法知道这句话到底是怎么来的,是“猜”出来的,还是真的在哪段训练数据里看过。这就好像你问一个人问题,他告诉你了答案,每句话都说“我觉得是对的”,但从来不给出处。
简单理解,传统语言模型用的是 n-gram 技术
1️⃣uni-gram 是看单个词
2️⃣bi-gram 是两个词连在一起
3️⃣tri-gram 是三个词组合
以上的语言逻辑会提供一部分上下文,但内容十分局限,只看现有的问题,根据小语句关联来回答,但忽视当前问题在整个对话的逻辑。
而 Infini-gram 是另一个思路。它不仅看现有问题,而是用一种类似“符号匹配”的方式,把模型输出的每个片段都拿去对照训练集里所有可能出现的“语句”,看它到底是从哪里学来的、和谁的贡献有关。
比如你问模型:“怎么判断一个钱包是Bot?”
一般的模型会告诉你:“这种地址通常在极短时间内高频交易多个DEX合约。”
它背后的技术其实挺硬核的,用的是基于 suffix-array 的 ∞-gram 框架 —— 本质上,它把训练集里所有片段都提前建好索引,输出的时候直接比对,不需要重新跑模型,也不靠梯度计算。这意味着快、稳、可复现。
对用户来说,你可以知道模型回答是不是“原创”还是“搬运”
对数据贡献者来说,你可以获得应有的“署名权”甚至“经济激励”
对监管机构来说,这提供了一个“可
简单理解,传统语言模型用的是 n-gram 技术
1️⃣uni-gram 是看单个词
2️⃣bi-gram 是两个词连在一起
3️⃣tri-gram 是三个词组合
以上的语言逻辑会提供一部分上下文,但内容十分局限,只看现有的问题,根据小语句关联来回答,但忽视当前问题在整个对话的逻辑。
而 Infini-gram 是另一个思路。它不仅看现有问题,而是用一种类似“符号匹配”的方式,把模型输出的每个片段都拿去对照训练集里所有可能出现的“语句”,看它到底是从哪里学来的、和谁的贡献有关。
比如你问模型:“怎么判断一个钱包是Bot?”
一般的模型会告诉你:“这种地址通常在极短时间内高频交易多个DEX合约。”
它背后的技术其实挺硬核的,用的是基于 suffix-array 的 ∞-gram 框架 —— 本质上,它把训练集里所有片段都提前建好索引,输出的时候直接比对,不需要重新跑模型,也不靠梯度计算。这意味着快、稳、可复现。
对用户来说,你可以知道模型回答是不是“原创”还是“搬运”
对数据贡献者来说,你可以获得应有的“署名权”甚至“经济激励”
对监管机构来说,这提供了一个“可
UNI-2.76%




- 赞赏
- 点赞
- 评论
- 分享
现在叙事的核心在讲 Interliquidity,我自己的理解是:不搞桥、不搞包装币、不搞孤岛链,而是让流动性从第一天就是“共享”的。
看看现在的现状,哪怕你是以太坊生态的头部 rollup,初期最痛的还是流动性冷启动。最多的问题就是钱在哪?人在哪?桥靠不靠谱?TVL 都得慢慢熬。
Sunrise 的想法是反过来干:你只管发链,流动性、DA、Gas、协议激励、生态绑定,系统来帮你接好,链上来就是满电启动,不用自己打地基。
Sunrise 最早其实是想解决 DA 的问题,所以一开始就做了个很超前的事——把 blob space 和流动性捆在一起。
从用户视角讲就是:你持有什么币,就直接用它操作全链,不用再手动换 gas 币。这个体验是超级顺滑的。
技术细节方面,Sunrise 的 DA 是那种真性能怪:
blob 编码全放链下,链上只放 Merkle root
payload 通过 P2P blob 网络分发,压根不挤链上 mempool。15 秒数据可用速度,现在市场上的主流项目都能跑通。
生态视角方面,现在 Sunrise 已经在对接 Eth、Sol、Bera等主流生态,未来 builder 在不同链上都可以接入 Sunrise 的 PoL 飞轮——大家共用一套流动性血管系统。
这个设想其实挺宏观的。可以把 Sunrise 看成是“未来链的液体底座”。比如你在上面发一条链,不需要
看看现在的现状,哪怕你是以太坊生态的头部 rollup,初期最痛的还是流动性冷启动。最多的问题就是钱在哪?人在哪?桥靠不靠谱?TVL 都得慢慢熬。
Sunrise 的想法是反过来干:你只管发链,流动性、DA、Gas、协议激励、生态绑定,系统来帮你接好,链上来就是满电启动,不用自己打地基。
Sunrise 最早其实是想解决 DA 的问题,所以一开始就做了个很超前的事——把 blob space 和流动性捆在一起。
从用户视角讲就是:你持有什么币,就直接用它操作全链,不用再手动换 gas 币。这个体验是超级顺滑的。
技术细节方面,Sunrise 的 DA 是那种真性能怪:
blob 编码全放链下,链上只放 Merkle root
payload 通过 P2P blob 网络分发,压根不挤链上 mempool。15 秒数据可用速度,现在市场上的主流项目都能跑通。
生态视角方面,现在 Sunrise 已经在对接 Eth、Sol、Bera等主流生态,未来 builder 在不同链上都可以接入 Sunrise 的 PoL 飞轮——大家共用一套流动性血管系统。
这个设想其实挺宏观的。可以把 Sunrise 看成是“未来链的液体底座”。比如你在上面发一条链,不需要
- 赞赏
- 点赞
- 评论
- 分享
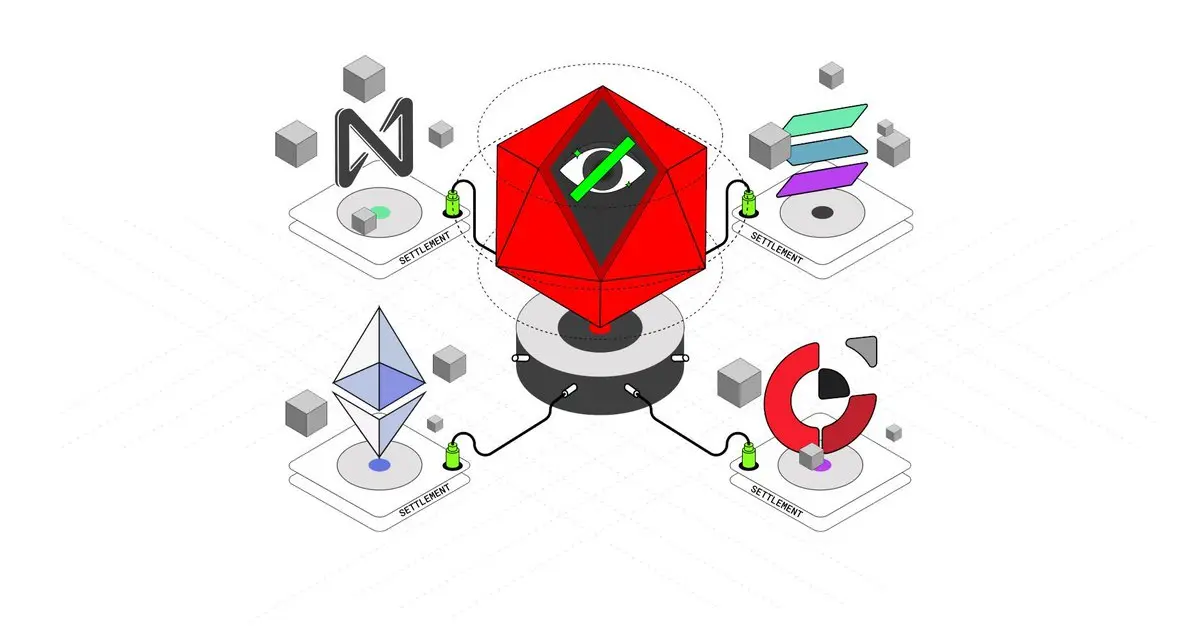
从我的理解来看,Anoma 不是在做另一个“更快更便宜”的智能合约链,他们更像是在思考:如果我们从头设计一套链,让它服务于隐私、表达和协商,那它会长什么样?
他们提的最多的一个关键词“intent-centric”
也就是“意图驱动”——听起来挺抽象,但其实很直白
简单来讲,目前通过Swap,在以太坊上,交易通过用户的明确指令进行,比如「我想用 A 换 B」,需要给到代币合约,通过链负责执行交易。
但在 Anoma 上,你可以只说「我想换成 B」,不需要管对手是谁、也不需要手动去撮合,链自己根据意图去找到匹配的交易对象,这个过程是匿名且自动的。当然在这个过程中我们看不到的操作可能是中间可能穿了 3 个协议、走了 2 条链。对于用户来讲是无感的!
除了原有生态的链外,anoma还做了一整套围绕“意图”的系统,包括 matcher、barter-style 协议、Zero-Knowledge 隐私层等等。
就好比以太坊像你去交易所下单——你得填表格,输入价格,点确认才能进行交易。
Anoma 更像你去咖啡店说“我想要点温的拿铁”,然后有人听到了,给你送过来,而且没人知道你是谁。
听起来有点抽象,但他们把这个流程设计得非常系统化,技术堆栈从 Namada(隐私支付)到 Juvix(安全语言),再到 Typhon(ZK 编译器),整个路线是那种“Change World”的感觉。
在 An
他们提的最多的一个关键词“intent-centric”
也就是“意图驱动”——听起来挺抽象,但其实很直白
简单来讲,目前通过Swap,在以太坊上,交易通过用户的明确指令进行,比如「我想用 A 换 B」,需要给到代币合约,通过链负责执行交易。
但在 Anoma 上,你可以只说「我想换成 B」,不需要管对手是谁、也不需要手动去撮合,链自己根据意图去找到匹配的交易对象,这个过程是匿名且自动的。当然在这个过程中我们看不到的操作可能是中间可能穿了 3 个协议、走了 2 条链。对于用户来讲是无感的!
除了原有生态的链外,anoma还做了一整套围绕“意图”的系统,包括 matcher、barter-style 协议、Zero-Knowledge 隐私层等等。
就好比以太坊像你去交易所下单——你得填表格,输入价格,点确认才能进行交易。
Anoma 更像你去咖啡店说“我想要点温的拿铁”,然后有人听到了,给你送过来,而且没人知道你是谁。
听起来有点抽象,但他们把这个流程设计得非常系统化,技术堆栈从 Namada(隐私支付)到 Juvix(安全语言),再到 Typhon(ZK 编译器),整个路线是那种“Change World”的感觉。
在 An
- 赞赏
- 点赞
- 评论
- 分享

人在梦中惊坐起 小丑竟是我自己?
其实大家明知道是ponzi还愿意参与的原因就是看上所谓的”透明“和”公平“。刚开始积分的造富效应或许从积分膨胀开始就变得不对劲了。拿回本周期来讲,早期投入virtual的用户早已经回本,甚至有的”纸手“在参与一些高倍率项目后赚的盆满钵满。目前投入参与virtual的用户,回本周期需要三个月甚至更长。对virtual的质押和 $VADER 的质押,大部分用户都是跟着社区的节奏去选择了质押。这一份质押其实也是一份信任,大家都希望社区好。至少没有人希望飞轮停滞下来。
坦率来讲,我觉得目前做的好的地方确实是项目方在改动。从听取社区意见的反馈到及时修复错误问题的过程中,解决问题的时间算的上是非常高效。基本上也能够应对社区发声的问题。给大部分人也能给到满意的答卷。
但是不透明的因素依旧存在,大家都知道Yapping的积分占比最近都是逐渐变低的。在积分”膨胀“的过程中,占比最大的其实是DAB的积分。我们当然知道需要流动性,但是流动性不光是让用户锁死。高质押低流动性散户是不砸盘了,但是币价一直下跌总是有问题的。
个人认为与其说按照目前的模式”通胀“,还不如根据定额的去通缩。每天固定积分,按不同类别的权重进行分类,且周期内分数清0。大家可能分拿的少一点。但是一定时期内的分数占比一致的情况下,可以对目前的现状进行改观。总量占比相对来说也比较好算,周期内项目的积分剩
其实大家明知道是ponzi还愿意参与的原因就是看上所谓的”透明“和”公平“。刚开始积分的造富效应或许从积分膨胀开始就变得不对劲了。拿回本周期来讲,早期投入virtual的用户早已经回本,甚至有的”纸手“在参与一些高倍率项目后赚的盆满钵满。目前投入参与virtual的用户,回本周期需要三个月甚至更长。对virtual的质押和 $VADER 的质押,大部分用户都是跟着社区的节奏去选择了质押。这一份质押其实也是一份信任,大家都希望社区好。至少没有人希望飞轮停滞下来。
坦率来讲,我觉得目前做的好的地方确实是项目方在改动。从听取社区意见的反馈到及时修复错误问题的过程中,解决问题的时间算的上是非常高效。基本上也能够应对社区发声的问题。给大部分人也能给到满意的答卷。
但是不透明的因素依旧存在,大家都知道Yapping的积分占比最近都是逐渐变低的。在积分”膨胀“的过程中,占比最大的其实是DAB的积分。我们当然知道需要流动性,但是流动性不光是让用户锁死。高质押低流动性散户是不砸盘了,但是币价一直下跌总是有问题的。
个人认为与其说按照目前的模式”通胀“,还不如根据定额的去通缩。每天固定积分,按不同类别的权重进行分类,且周期内分数清0。大家可能分拿的少一点。但是一定时期内的分数占比一致的情况下,可以对目前的现状进行改观。总量占比相对来说也比较好算,周期内项目的积分剩
- 赞赏
- 点赞
- 评论
- 分享
真香警告,VADER的坚守者!
有谁能拒绝一天2万份的 $VADER 积分呢!自从改版过后基本上每天稳定都在一万多分,简直是嘴撸者的福音。大家投入时间精力,最终的目的还是为了收获。对比隔壁的某嘴撸项目,我觉得至少Virtual没有让人那么失望。也不会在数值上去玩所谓的文字游戏。目前看来反馈机制和团队反应都算的上迅速。
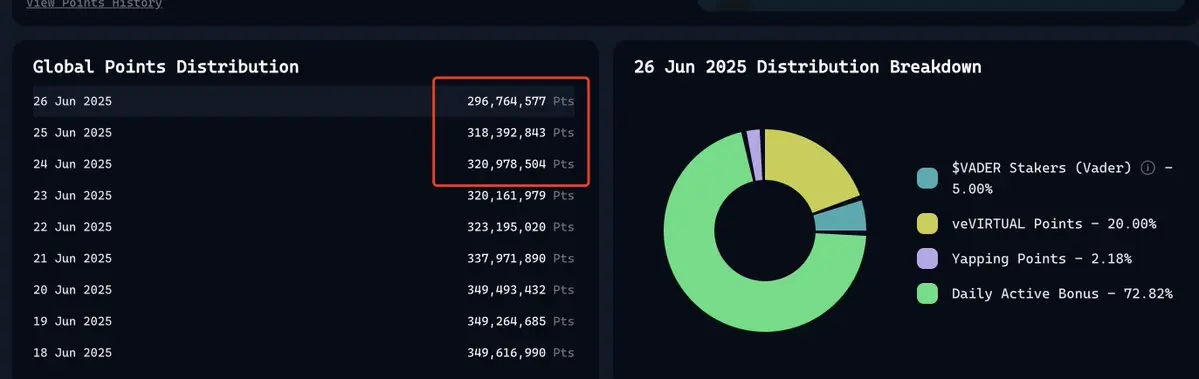
目前VADER的排行榜也是每天都在重置,需要每天源源不断的去Yapping。对生态本身就是一种正向激励,目前来看最欣慰的就是每日的积分总量开始逐渐变得通缩了。
昨天也是正式下降到了3亿以下,对于Yapping的分配也从2.36%降低到了2.18%。虽然总量上得到的积分少了,但是从生态角度来讲,在没有优质项目的时候将总量积分进行通缩其实也是下定了决心的。至少大额分配都在DAB上面,很多用户对于总体的数据不太敏感的时候就会十分在意自己的DAB评分,一旦分数出现下降后,对于大额投入玩家在社区中的质疑就会接踵而至,之前看到有帖子讨论过说virtual需要拿出壮士断腕的决心,目前来看他们的策略基本上是通过多维度的积分统计来稀释积分在某一权重类型上面的高额占比。
有谁能拒绝一天2万份的 $VADER 积分呢!自从改版过后基本上每天稳定都在一万多分,简直是嘴撸者的福音。大家投入时间精力,最终的目的还是为了收获。对比隔壁的某嘴撸项目,我觉得至少Virtual没有让人那么失望。也不会在数值上去玩所谓的文字游戏。目前看来反馈机制和团队反应都算的上迅速。
目前VADER的排行榜也是每天都在重置,需要每天源源不断的去Yapping。对生态本身就是一种正向激励,目前来看最欣慰的就是每日的积分总量开始逐渐变得通缩了。
昨天也是正式下降到了3亿以下,对于Yapping的分配也从2.36%降低到了2.18%。虽然总量上得到的积分少了,但是从生态角度来讲,在没有优质项目的时候将总量积分进行通缩其实也是下定了决心的。至少大额分配都在DAB上面,很多用户对于总体的数据不太敏感的时候就会十分在意自己的DAB评分,一旦分数出现下降后,对于大额投入玩家在社区中的质疑就会接踵而至,之前看到有帖子讨论过说virtual需要拿出壮士断腕的决心,目前来看他们的策略基本上是通过多维度的积分统计来稀释积分在某一权重类型上面的高额占比。

- 赞赏
- 点赞
- 评论
- 分享
Virtual 虐我千百遍 我待Virtual如初恋
“想要让人亡,必先让人狂”
其实自己的Virtual Yapping分数一直还算中上的水平,即使是算法改变后基本上每天也有一万多的积分。在“自作聪明”的提前去提各种 $VADER 的话题,直至出分前也依旧以为自己是前排,出分后成了“落榜美术生”。
押中了所有的题目,理解了所有的题意。最终却考了0分!
相比较各位老师的高分,而我就是那个 $VADER 新人。昨天去掉 $VADER 的积分的500分,实际VADER Yapping是700分。
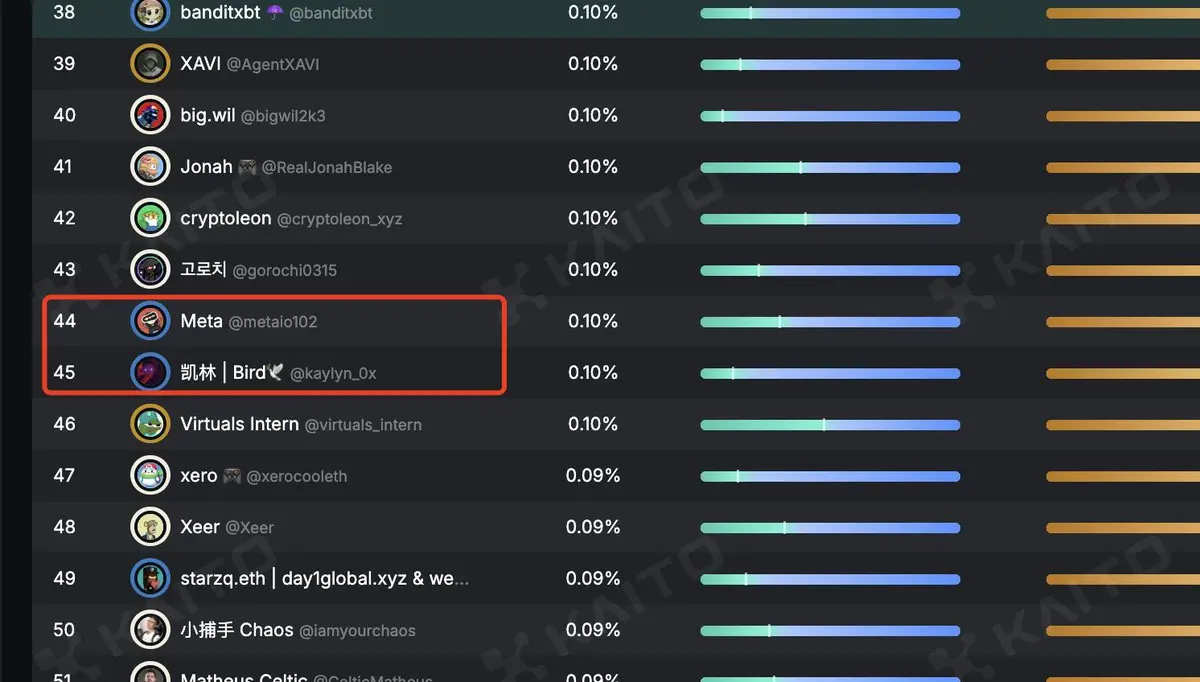
Kaito 的榜单 我和凯琳老师基本差不多,都在四十多名。如果按照Yaps的基础分数,对比下来我也是比他高的。 Arbus score 的分数我在100分左右,对比其他的用户应该是要高一些的。
“想要让人亡,必先让人狂”
其实自己的Virtual Yapping分数一直还算中上的水平,即使是算法改变后基本上每天也有一万多的积分。在“自作聪明”的提前去提各种 $VADER 的话题,直至出分前也依旧以为自己是前排,出分后成了“落榜美术生”。
押中了所有的题目,理解了所有的题意。最终却考了0分!
相比较各位老师的高分,而我就是那个 $VADER 新人。昨天去掉 $VADER 的积分的500分,实际VADER Yapping是700分。
Kaito 的榜单 我和凯琳老师基本差不多,都在四十多名。如果按照Yaps的基础分数,对比下来我也是比他高的。 Arbus score 的分数我在100分左右,对比其他的用户应该是要高一些的。

- 赞赏
- 点赞
- 评论
- 分享